Druid Data Cookbook: Upserts in Druid SQL

In an earlier blog, I demonstrated a technique to combine existing and new data in Druid batch ingestion in a way that more or less emulates what is usually expressed in SQL as a MERGE or UPSERT statement. This technique involves a combine datasource and works only in JSON-based ingestion. Also, it works on bulk data where you replace an entire range of data based on a time interval and key range.
Today I am going to look at a similar, albeit more surgical construction, implementing what is usually expressed in SQL as a MERGE or UPSERT statement. I will be using SQL based ingestion that is available in newer versions of Druid.
The MERGE statement, in a simplified way, works like this:
MERGE INTO druid_table
(SELECT * FROM external_table)
ON druid_table.keys = external_table.keys
WHEN MATCHED THEN UPDATE ...
WHEN NOT MATCHED THEN INSERT ...
So, you compare old (druid_table) and new data (external_table) with respect to a matching condition. This would entail a combination of timestamp and key fields, which in the above pseudocode is denoted by keys. There are three possible outcomes for any combination of keys:
- If keys exists only in druid table, leave these data untouched.
- If keys exists in both tables, replace the row(s) in druid_table with those in external_table.
- If keys exists only in external_table, insert that data into druid_table.
But Druid SQL does not offer a MERGE statement, at least not at the time of this writing. Can we do this in SQL anyway? Stay tuned if you want to know!
This tutorial works with the Druid 28 quickstart.
Recap: the data
Let’s use the same data as in the bulk upsert blog: daily aggregated viewership data from various ad networks.
{"date": "2023-01-01T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 2770, "ads_revenue": 330.69}
{"date": "2023-01-01T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 9646, "ads_revenue": 137.85}
{"date": "2023-01-01T00:00:00Z", "ad_network": "twottr", "ads_impressions": 1139, "ads_revenue": 493.73}
{"date": "2023-01-02T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 9066, "ads_revenue": 368.66}
{"date": "2023-01-02T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 4426, "ads_revenue": 170.96}
{"date": "2023-01-02T00:00:00Z", "ad_network": "twottr", "ads_impressions": 9110, "ads_revenue": 452.2}
{"date": "2023-01-03T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 3275, "ads_revenue": 363.53}
{"date": "2023-01-03T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 9494, "ads_revenue": 426.37}
{"date": "2023-01-03T00:00:00Z", "ad_network": "twottr", "ads_impressions": 4325, "ads_revenue": 107.44}
{"date": "2023-01-04T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 8816, "ads_revenue": 311.53}
{"date": "2023-01-04T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 8955, "ads_revenue": 254.5}
{"date": "2023-01-04T00:00:00Z", "ad_network": "twottr", "ads_impressions": 6905, "ads_revenue": 211.74}
{"date": "2023-01-05T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 3075, "ads_revenue": 382.41}
{"date": "2023-01-05T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 4870, "ads_revenue": 205.84}
{"date": "2023-01-05T00:00:00Z", "ad_network": "twottr", "ads_impressions": 1418, "ads_revenue": 282.21}
{"date": "2023-01-06T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 7413, "ads_revenue": 322.43}
{"date": "2023-01-06T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 1251, "ads_revenue": 265.52}
{"date": "2023-01-06T00:00:00Z", "ad_network": "twottr", "ads_impressions": 8055, "ads_revenue": 394.56}
{"date": "2023-01-07T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 4279, "ads_revenue": 317.84}
{"date": "2023-01-07T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 5848, "ads_revenue": 162.96}
{"date": "2023-01-07T00:00:00Z", "ad_network": "twottr", "ads_impressions": 9449, "ads_revenue": 379.21}
Save this file as data1.json. Also, save the “new data” bit:
{"date": "2023-01-03T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 4521, "ads_revenue": 378.65}
{"date": "2023-01-04T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 4330, "ads_revenue": 464.02}
{"date": "2023-01-05T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 6088, "ads_revenue": 320.57}
{"date": "2023-01-06T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 3417, "ads_revenue": 162.77}
{"date": "2023-01-07T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 9762, "ads_revenue": 76.27}
{"date": "2023-01-08T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 1484, "ads_revenue": 188.17}
{"date": "2023-01-09T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 1845, "ads_revenue": 287.5}
as data2.json.
Initial data ingestion
Let’s ingest the first data set. We want to set the segment granularity to month, so the ingestion statement uses a PARTITIONED BY MONTH clause. Moreover, we enforce secondary partitioning by choosing REPLACE mode and by including a CLUSTERED BY clause. Here’s the complete statement (replace the path in baseDir with the path you saved the sample file to):
REPLACE INTO "ad_data" OVERWRITE ALL
WITH "ext" AS (
SELECT *
FROM TABLE(
EXTERN(
'{"type":"local","baseDir":"/<my base path>","filter":"data1.json"}',
'{"type":"json"}'
)
) EXTEND ("date" VARCHAR, "ad_network" VARCHAR, "ads_impressions" BIGINT, "ads_revenue" DOUBLE)
)
SELECT
TIME_PARSE("date") AS "__time",
"ad_network",
"ads_impressions",
"ads_revenue"
FROM "ext"
PARTITIONED BY MONTH
CLUSTERED BY "ad_network"
You can run this SQL from the Query tab in the Druid console:
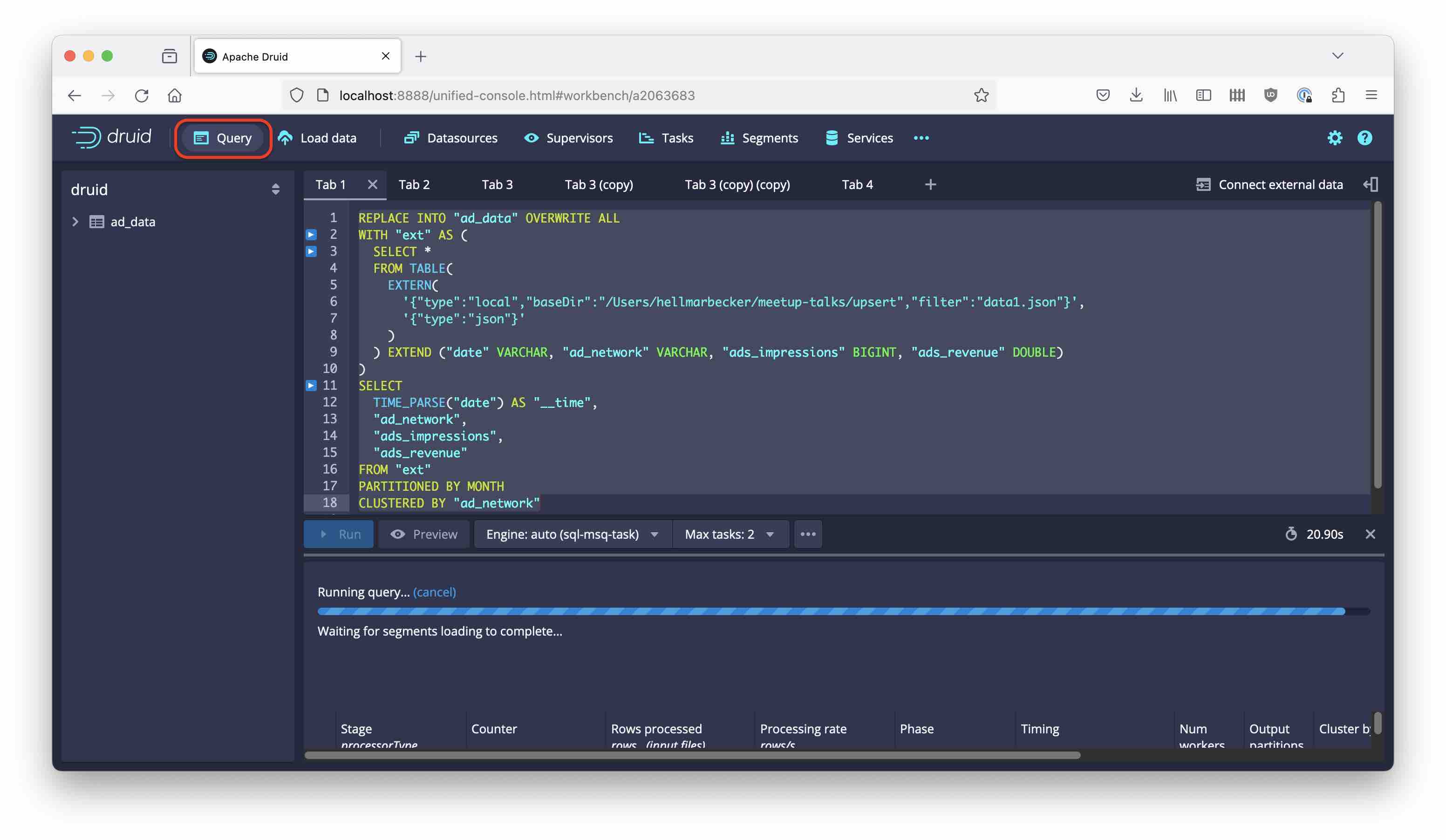
Or you can use the Ingest wizard to enter the same code.
The merge query
Many thanks to John Kowtko for pointing out this approach. Since we don’t have a MERGE statement, let’s emulate it using a FULL OUTER JOIN. Druid’s MSQ engine supports sort/merge joins of arbitrary size tables, so we can actually pull this off!
Important note: the new join algorithm needs to be explicitly requested by setting a query context parameter. Open up the query engine menu next to the Preview button, and select Edit context:
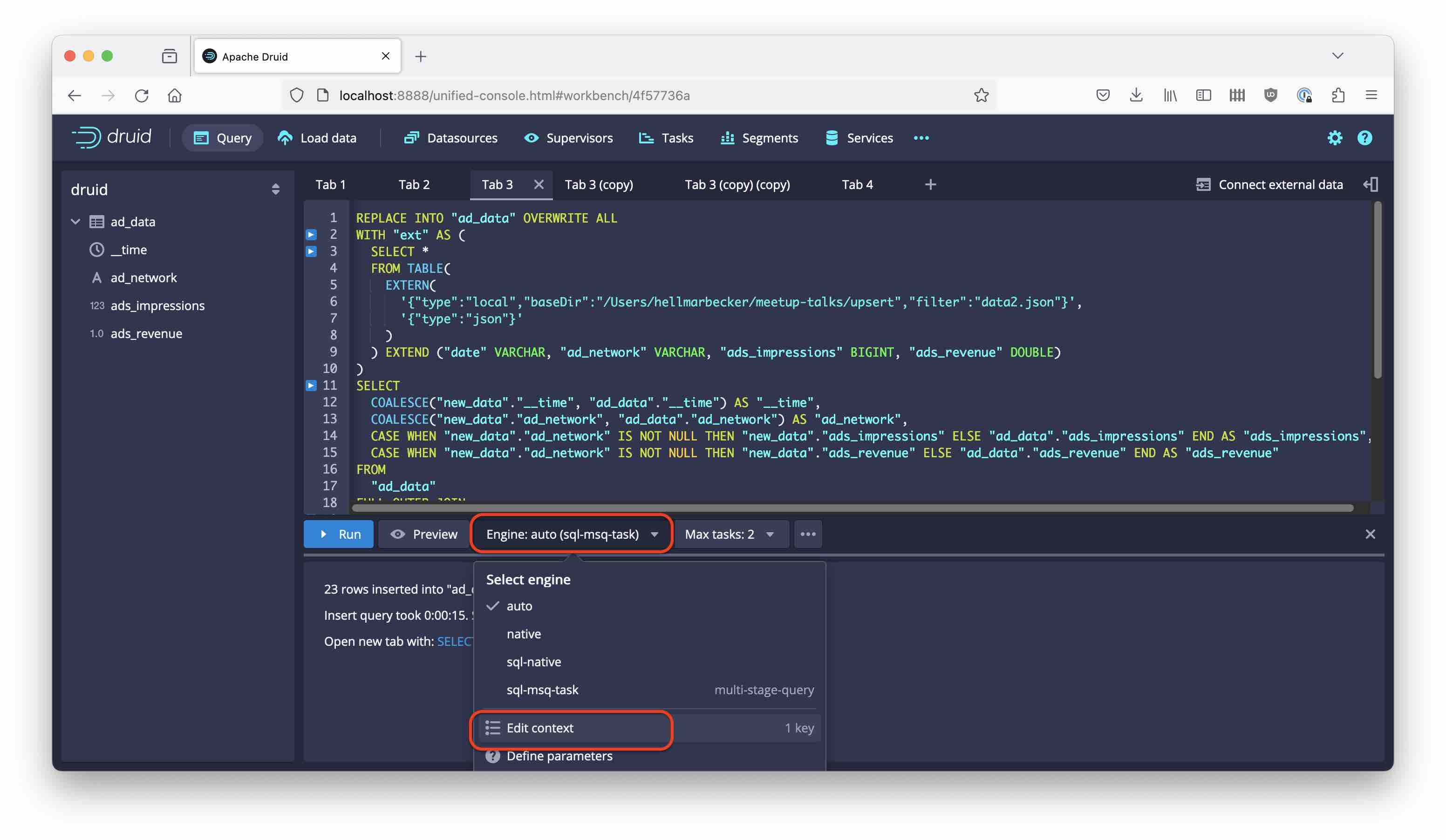
Add { "sqlJoinAlgorithm": "sortMerge" } to the query context.
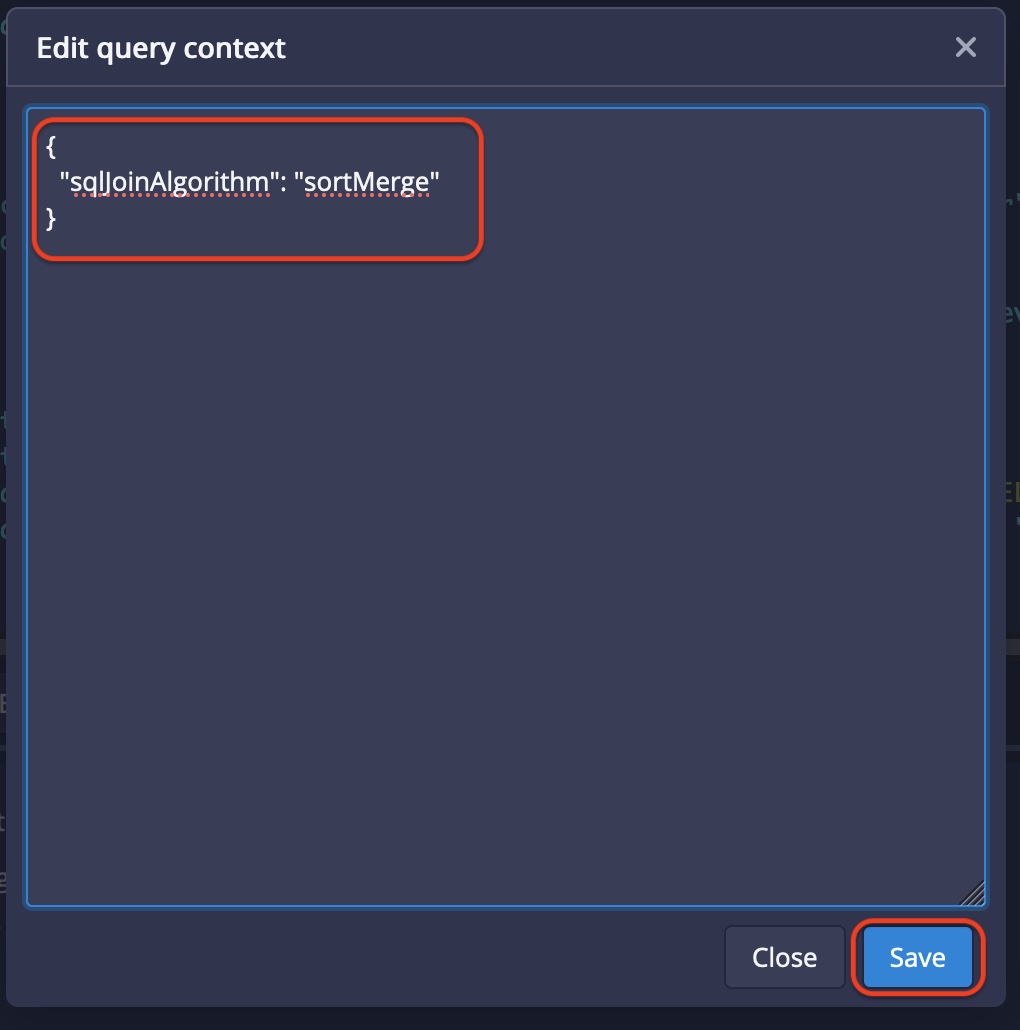
Then run the ingestion query:
REPLACE INTO "ad_data" OVERWRITE ALL
WITH "ext" AS (
SELECT *
FROM TABLE(
EXTERN(
'{"type":"local","baseDir":"/<my base path>","filter":"data2.json"}',
'{"type":"json"}'
)
) EXTEND ("date" VARCHAR, "ad_network" VARCHAR, "ads_impressions" BIGINT, "ads_revenue" DOUBLE)
)
SELECT
COALESCE("new_data"."__time", "ad_data"."__time") AS "__time",
COALESCE("new_data"."ad_network", "ad_data"."ad_network") AS "ad_network",
CASE WHEN "new_data"."ad_network" IS NOT NULL THEN "new_data"."ads_impressions" ELSE "ad_data"."ads_impressions" END AS "ads_impressions",
CASE WHEN "new_data"."ad_network" IS NOT NULL THEN "new_data"."ads_revenue" ELSE "ad_data"."ads_revenue" END AS "ads_revenue"
FROM
"ad_data"
FULL OUTER JOIN
( SELECT
TIME_PARSE("date") AS "__time",
"ad_network",
"ads_impressions",
"ads_revenue"
FROM "ext" ) "new_data"
ON "ad_data"."__time" = "new_data"."__time" AND "ad_data"."ad_network" = "new_data"."ad_network"
PARTITIONED BY MONTH
CLUSTERED BY "ad_network"
Analysis of the query
What have we done here?
We are emulating the MERGE statement with a full outer join. The left side table is the data we already have in Druid; the right side is the new data. Our merge key is a combination of timestamp (daily granularity) and ad network.
For each key combination there are three possible outcomes:
- If the right hand side is null, leave the left hand side data as the result (leave old data untouched).
- If neither side is null, replace the row(s) in the existing table with new data from the right hand side (update rows).
- If the left hand side is null, insert the right hand side data into Druid.
This is exactly what we wanted to happen.
In order to identify the correct data to be inserted, we look at the join key:
- Data rows that refer to key fields are modeled with a
COALESCEstatement:COALESCE("new_data"."ad_network", "ad_data"."ad_network") AS "ad_network"selects the key field from the right hand side, and if that one is null (right hand side doesn’t exist), then the left hand side instead. - For non-key fields the statement is a bit more complex because we still have to select based on the key field. Otherwise some real null values in the data might create inconsistencies, where we would overwrite rows only partially. Hence an expression like
CASE WHEN "new_data"."ad_network" IS NOT NULL THEN "new_data"."ads_impressions" ELSE "ad_data"."ads_impressions" END AS "ads_impressions".
Can we be more selective?
You might be thinking that this approach entails rewriting all the data in the existing table, even if the range of new data is much more limited. And you would be right. Fortunately, it is possible to limit the date range to be overwritten.
Let’s try this. Apparently we can specify the date range like so:
REPLACE INTO "ad_data" OVERWRITE WHERE __time >= TIMESTAMP'2023-01-03' AND __time < TIMESTAMP'2023-01-10'
...
Alas, this doesn’t work:
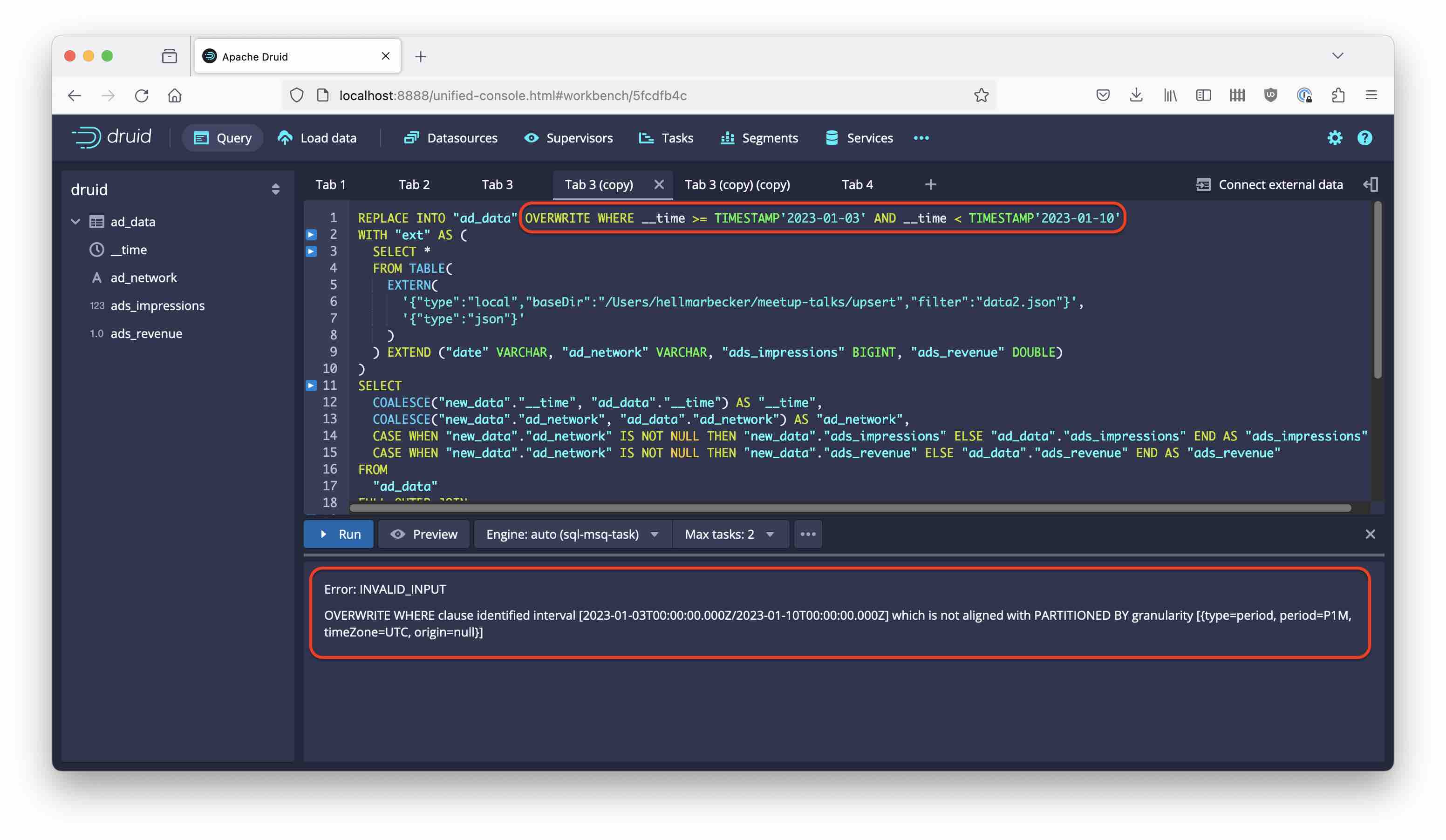
The date filter has to be aligned with the segments, otherwise Druid will refuse to run the query. This is actually a Good Thing: in JSON ingestion mode you would be able to overwrite a whole segment with data covering a lesser date range, potentially deleting data that you actually wanted to keep!
If we adjust the date range clause to match the segment boundaries:
REPLACE INTO "ad_data" OVERWRITE WHERE __time >= TIMESTAMP'2023-01-01' AND __time < TIMESTAMP'2023-02-01'
...
the ingestion query works fine and we get the desired result:
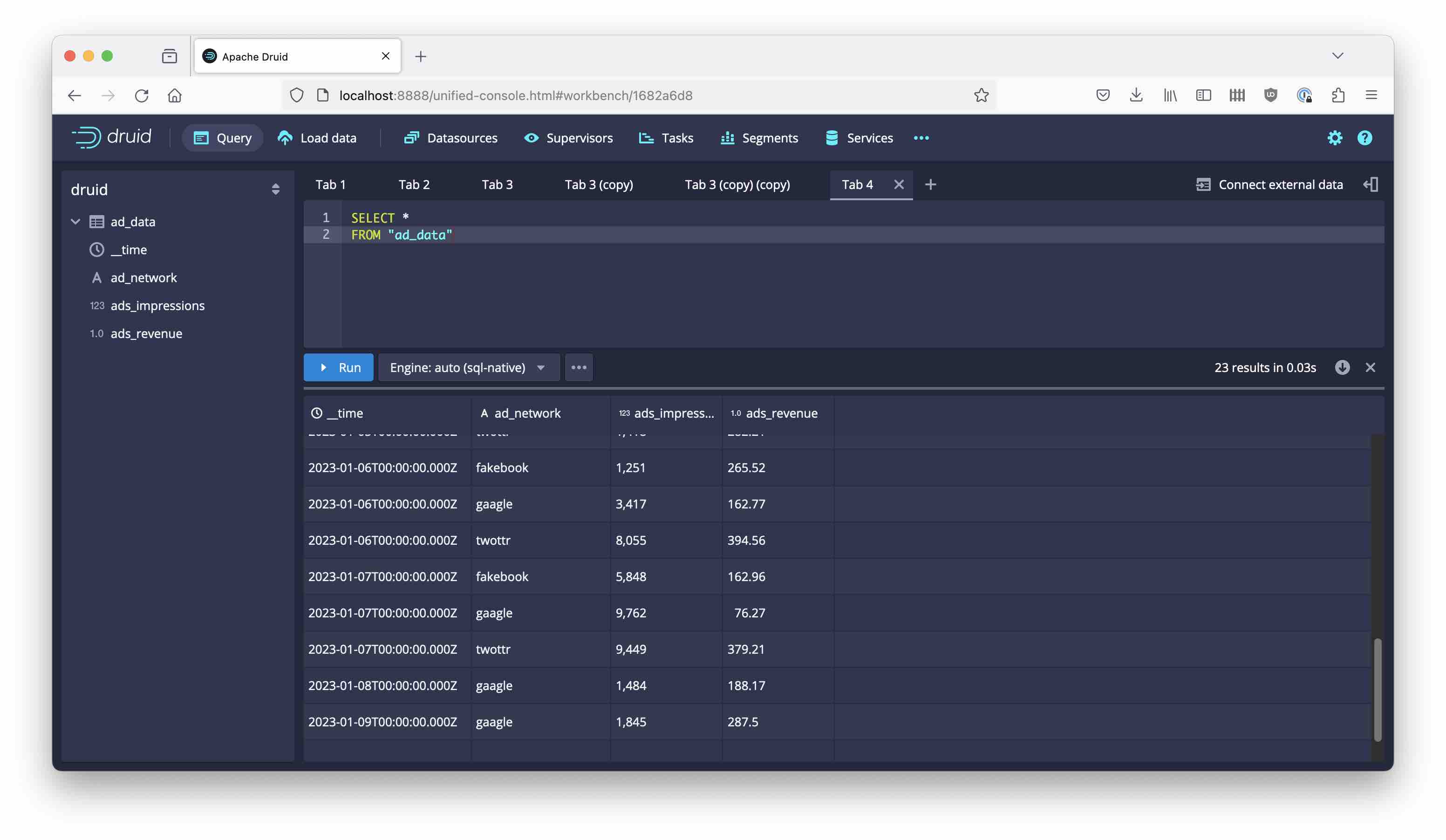
Use the new graphical exploration mode of Druid to get an idea of the data:
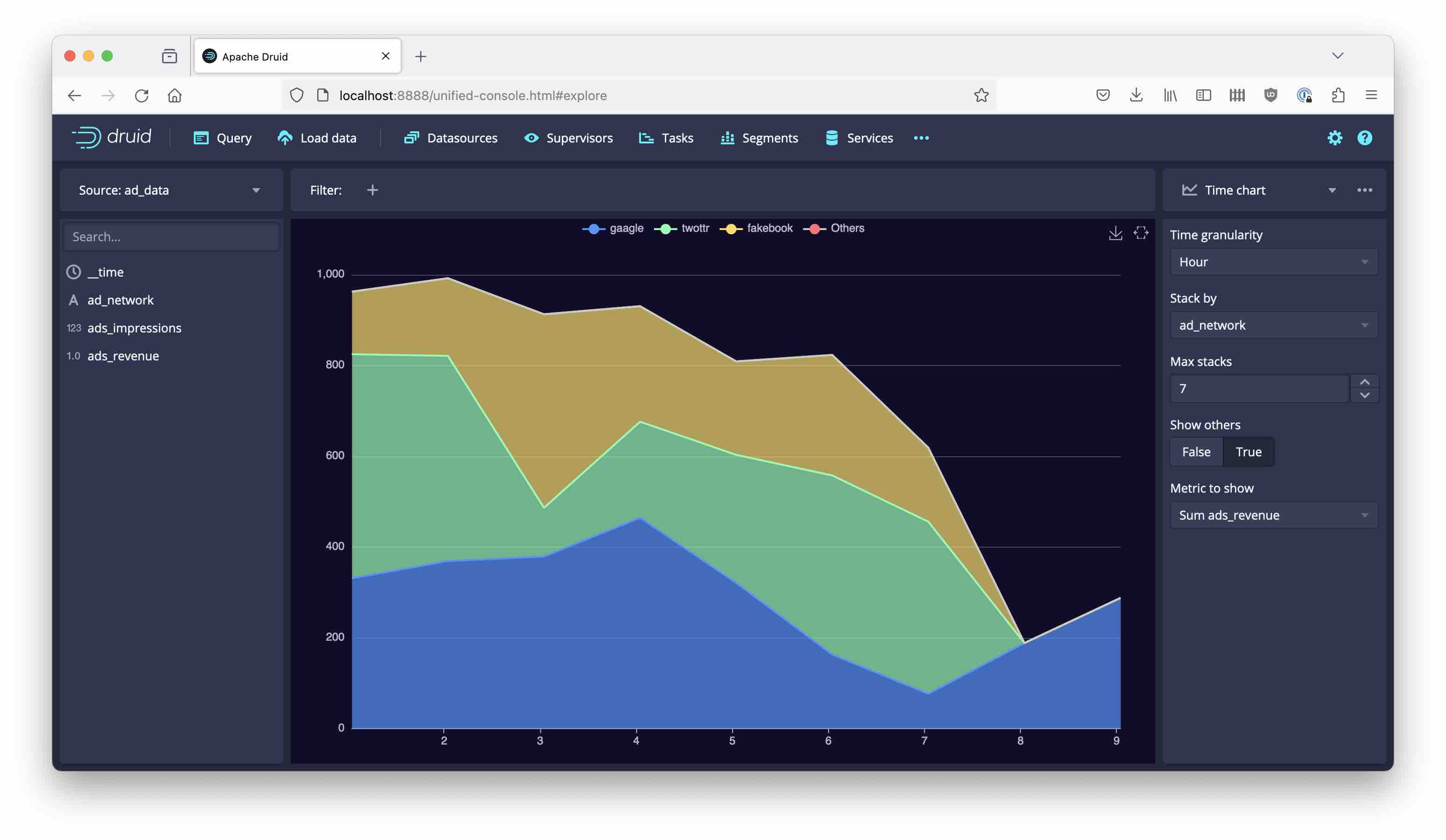
Learnings
- You can emulate the effect of a
MERGEstatement in Druid with a full outer join. - Make sure to enable the sort/merge join algorithm in the query context.
- Some consideration must be taken around null values in the outer join result.
- You can limit the range of data for reprocessing using
OVERWRITE WHERE ..., but take care to align the time filter with your segment granularity.
“This image is taken from Page 500 of Praktisches Kochbuch für die gewöhnliche und feinere Küche” by Medical Heritage Library, Inc. is licensed under CC BY-NC-SA 2.0 ![]()
![]()
![]()
![]() .
.