Using Druid with MinIO
With on premise setups, compute/storage separation is often implemented using a NAS or similar storage unit that exposes an S3 API endpoint.
I want to emulate S3 related behavior in a self contained demo that I can run on my laptop without an internet connection. This is conveniently done using MinIO as my S3 compatible storage.
Let’s deploy MinIO using this docker compose file:
version: "3"
services:
minio:
image: minio/minio
container_name: minio
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
minio_net:
aliases:
- druid.minio
ports:
- 9001:9001
- 9000:9000
command: ["server", "/data", "--console-address", ":9001"]
mc:
depends_on:
- minio
image: minio/mc
container_name: mc
networks:
minio_net:
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
entrypoint: >
/bin/sh -c "
until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;
/usr/bin/mc rm -r --force minio/indata;
/usr/bin/mc mb minio/indata;
/usr/bin/mc policy set public minio/indata;
/usr/bin/mc rm -r --force minio/deepstorage;
/usr/bin/mc mb minio/deepstorage;
/usr/bin/mc policy set public minio/deepstorage;
tail -f /dev/null
"
networks:
minio_net:
Save this file as docker-compose.yaml to your work directory and run the command
docker compose up -d
This gives us a MinIO instance and the mc client. It will also automatically create two buckets in MinIO, named indata and deepstorage, that we will need for this tutorial. If you point your browser to localhost:9000, you can verify that the buckets have been created:
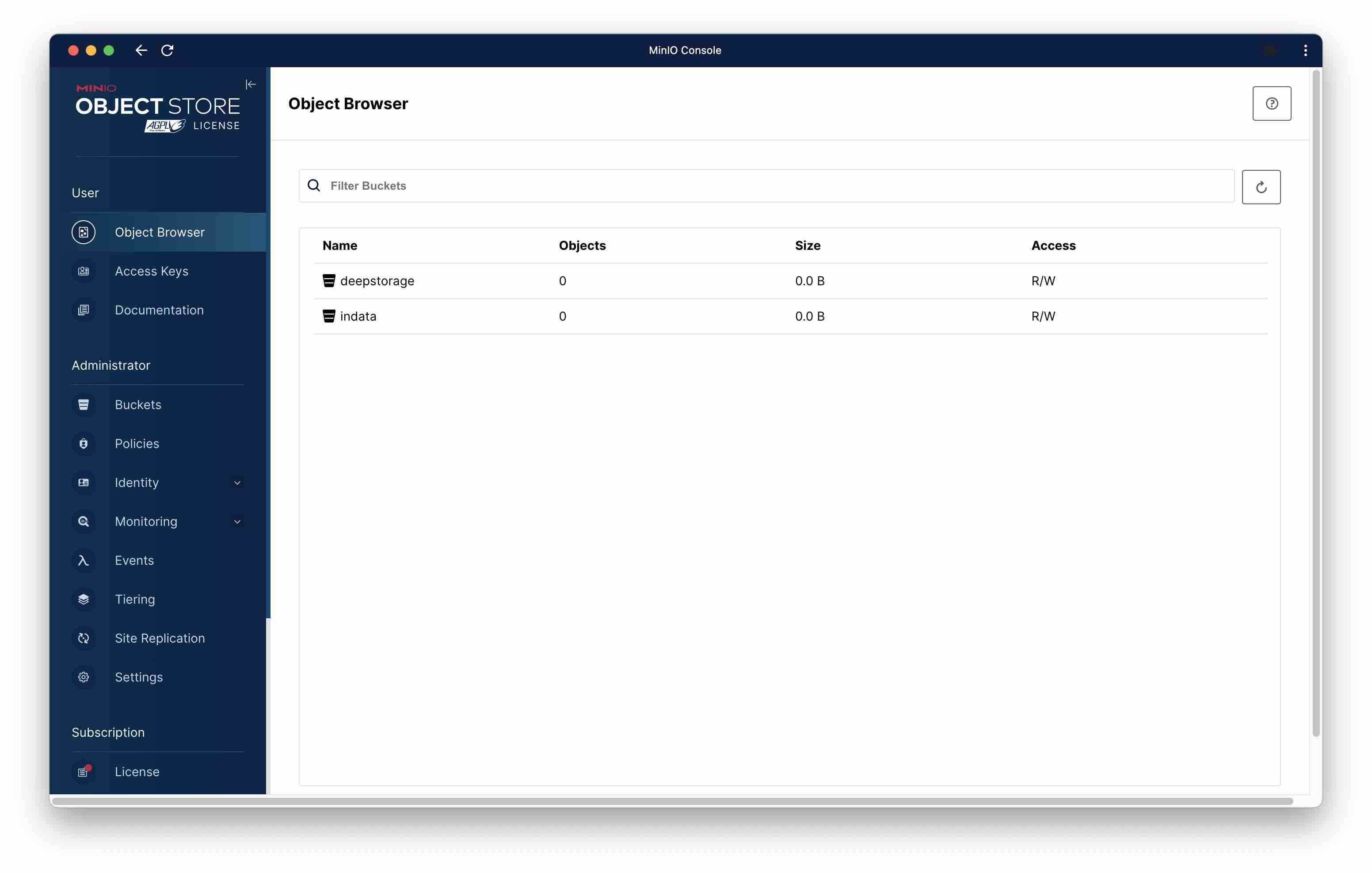
(Kudos to Tabular from whose GitHub repository I adapted the docker compose file.)
Configuring MinIO as deep storage and log target
I am using the standard Druid 27.0 quickstart. If you want to start Druid using the new start-druid script, you find the relevant configuration settings in conf/druid/auto/_common/common.runtime.properties under your Druid installation directory.
First of all, we need to load the S3 extension by adding it to the load list - it should look similar to this:
druid.extensions.loadList=["druid-s3-extensions", "druid-hdfs-storage", "druid-kafka-indexing-service", "druid-datasketches", "druid-multi-stage-query"]
Also configure the S3 default settings (endpoint, authentication):
druid.s3.accessKey=admin
druid.s3.secretKey=password
druid.s3.protocol=http
druid.s3.enablePathStyleAccess=true
druid.s3.endpoint.signingRegion=us-east-1
druid.s3.endpoint.url=http://localhost:9000/
For using MinIO as deep storage, comment out the default settings for druid.storage.*, and insert this section instead:
druid.storage.type=s3
druid.storage.bucket=deepstorage
druid.storage.baseKey=segments
Likewise, change the default configuration for the indexer logs to:
druid.indexer.logs.type=s3
druid.indexer.logs.s3Bucket=deepstorage
druid.indexer.logs.s3Prefix=indexing-logs
Then start Druid like this:
bin/start-druid -m5g
Ingesting data from MinIO
By default, Druid uses the same settings in common.runtime.properties for ingestion from S3, too. So for instance, you can upload the wikipedia data sample to the indata bucket in your MinIO instance and we take advantage of the same settings as for deep storage. Just use s3://indata/ as the S3 prefix in the ingestion wizard, and it should work out of the box.
Here is my example JSON ingestion spec:
{
"type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "s3",
"prefixes": [
"s3://indata/"
]
},
"inputFormat": {
"type": "json"
}
},
"tuningConfig": {
"type": "index_parallel",
"partitionsSpec": {
"type": "dynamic"
}
},
"dataSchema": {
"dataSource": "wikipedia_s3_2",
"timestampSpec": {
"column": "time",
"format": "iso"
},
"granularitySpec": {
"queryGranularity": "none",
"rollup": false,
"segmentGranularity": "day"
},
"dimensionsSpec": {
"dimensions": [
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
{
"type": "long",
"name": "delta"
},
{
"type": "long",
"name": "added"
},
{
"type": "long",
"name": "deleted"
}
]
}
}
}
}
Or in SQL (using the automatic conversion function):
REPLACE INTO "wikipedia_s3_2" OVERWRITE ALL
WITH "source" AS (SELECT * FROM TABLE(
EXTERN(
'{"type":"s3","prefixes":["s3://indata/"]}',
'{"type":"json"}'
)
) EXTEND ("time" VARCHAR, "channel" VARCHAR, "cityName" VARCHAR, "comment" VARCHAR, "countryIsoCode" VARCHAR, "countryName" VARCHAR, "isAnonymous" VARCHAR, "isMinor" VARCHAR, "isNew" VARCHAR, "isRobot" VARCHAR, "isUnpatrolled" VARCHAR, "metroCode" VARCHAR, "namespace" VARCHAR, "page" VARCHAR, "regionIsoCode" VARCHAR, "regionName" VARCHAR, "user" VARCHAR, "delta" BIGINT, "added" BIGINT, "deleted" BIGINT))
SELECT
TIME_PARSE("time") AS "__time",
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
"delta",
"added",
"deleted"
FROM "source"
PARTITIONED BY DAY
In either case, you can easily verify that both the segment files and the indexer logs end up in MinIO.
Changing the endpoint settings in the ingestion command
Now let’s go back to local deep storage, so that we cannot take advantage of endpoint settings that are baked into the service properties file. Hence we need to establish those settings right in the ingestion spec.
Restore the common properties to their default values and restart Druid. (You still need the S3 extension loaded.)
JSON version
Start the wizard as for a standard S3 ingestion. Then switch to the JSON view and edit the S3 settings in the ingestion spec:
"inputSource": {
"type": "s3",
"prefixes": [
"s3://indata/"
],
"properties": {
"accessKeyId": {
"type": "default",
"password": "admin"
},
"secretAccessKey": {
"type": "default",
"password": "password"
}
},
"endpointConfig": {
"url": "http://localhost:9000",
"signingRegion": "us-east-1"
},
"clientConfig": {
"disableChunkedEncoding": true,
"enablePathStyleAccess": true,
"forceGlobalBucketAccessEnabled": false
}
}
Note: In this case, because we are using plain HTTP, we need to include the http:// in the endpoint URL. If we put it in the clientConfig.protocol, as you might think from the sample in the documentation, it is not recognized.
SQL version
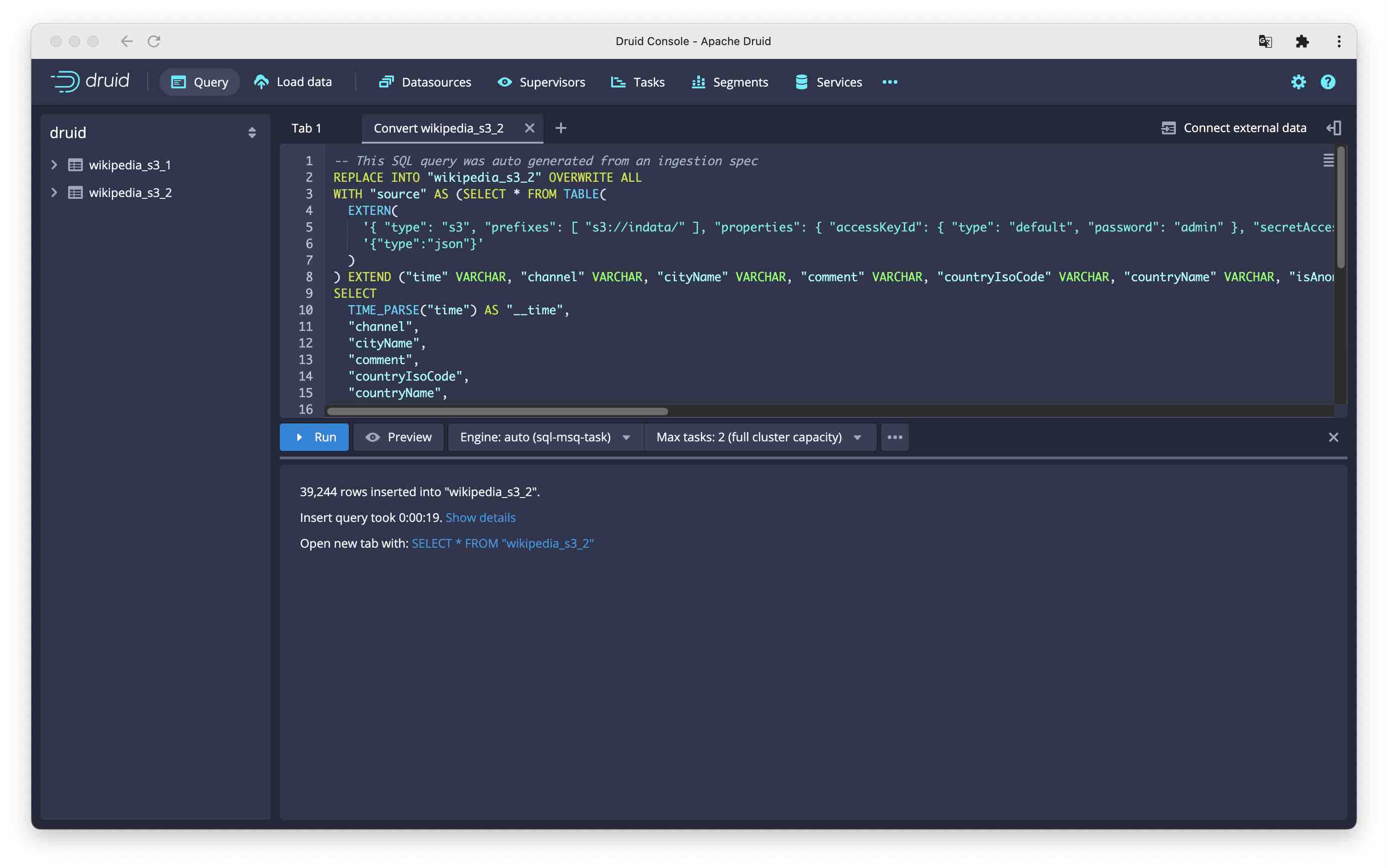
In the SQL version, we copy the same settings into the EXTERN statement, like so:
REPLACE INTO "wikipedia_s3_2" OVERWRITE ALL
WITH "source" AS (SELECT * FROM TABLE(
EXTERN(
'{ "type": "s3", "prefixes": [ "s3://indata/" ], "properties": { "accessKeyId": { "type": "default", "password": "admin" }, "secretAccessKey": { "type": "default", "password": "password" } }, "endpointConfig": { "url": "http://localhost:9000", "signingRegion": "us-east-1" }, "clientConfig": { "disableChunkedEncoding": true, "enablePathStyleAccess": true, "forceGlobalBucketAccessEnabled": false } }',
'{"type":"json"}'
)
) EXTEND ("time" VARCHAR, "channel" VARCHAR, "cityName" VARCHAR, "comment" VARCHAR, "countryIsoCode" VARCHAR, "countryName" VARCHAR, "isAnonymous" VARCHAR, "isMinor" VARCHAR, "isNew" VARCHAR, "isRobot" VARCHAR, "isUnpatrolled" VARCHAR, "metroCode" VARCHAR, "namespace" VARCHAR, "page" VARCHAR, "regionIsoCode" VARCHAR, "regionName" VARCHAR, "user" VARCHAR, "delta" BIGINT, "added" BIGINT, "deleted" BIGINT))
SELECT
TIME_PARSE("time") AS "__time",
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
"delta",
"added",
"deleted"
FROM "source"
PARTITIONED BY DAY
Conclusion
- You can use MinIO or another S3 compatible storage with Druid. You configure the endpoint, protocol, and authentication settings in the common properties file.
- If you need to ingest from a different MinIO instance, or you want to use MinIO for ingestion only, you can set or override the S3 settings in the ingestion spec. This works both in JSON and SQL mode.
- Either way, make sure you have the S3 extension loaded.