Analyzing GitHub Stars with Imply Polaris

Why all this?
A while ago, Will asked if we could measure community engagement in the Apache Druid community by analyzing the number of GitHub stars that the Druid source repository got over time. He wanted to compare that development with other repositories within the realtime analytics ecosystem, and possibly identify segments of GitHub users that had starred multiple repositories out of the list we are looking at.
This blog is not about the results of that endeavor. Instead, I am going to look at an interesting data/query modeling problem I encountered on the way.
The dataset
Let’s get the stargazers for various repos that are either competitive or complementary with druid. This includes
- other realtime analytics datastores
- streaming platforms
- stream processors
- frontend (business intelligence) tools.
For each stargazer record, we store
- the user
- the repository
- date and time when it was starred; this will be the primary timestamp for the Druid data model.
How to get the data
The data we are going to analyze comes from the GitHub stargazers API. Vijay has written a great blog about this; I am using a simpler approach with a Python script that runs once and tries to retrieve all the data.
This probably warrants another blog about the quirks of the GitHub API, so for now let a few remarks suffice.
- Surprise: Elon Musk did not invent API rate limiting! Our first idea was to get all the repositories that Druid stargazers also starred. This approach is not viable.
- There are primary (hard) and secondary rate limits. Either way, if you hit a limit, GitHub throws a 403 error at you. The required action depends on the type of rate limit that was applied, and this needs to be parsed from response headers.
- The API imposes pagination with a maximum page size of 100 records.
- The maximum page index you can retrieve is 399.
- As a consequence, you will not get more than 40,000 stars for any one repository, which will soon become important.
You can find the code that I used, as well as all the SQL samples from this post, in my GitHub repository.
Loading the data into Polaris
While the basic SQL analysis works just as well with open source Druid, I am using Imply Polaris because of its ease of use and built in visualization. Ingesting file data into Polaris is a streamlined process that is well described in the quickstart guide - follow the instructions there.
Here are some sample records from my script:
{"starred_at": "2012-10-23T19:08:07Z", "user": {"login": "bennettandrews", "id": 1143, "node_id": "MDQ6VXNlcjExNDM=", "avatar_url": "https://avatars.githubusercontent.com/u/1143?v=4", "gravatar_id": "", "url": "https://api.github.com/users/bennettandrews", "html_url": "https://github.com/bennettandrews", "followers_url": "https://api.github.com/users/bennettandrews/followers", "following_url": "https://api.github.com/users/bennettandrews/following{/other_user}", "gists_url": "https://api.github.com/users/bennettandrews/gists{/gist_id}", "starred_url": "https://api.github.com/users/bennettandrews/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/bennettandrews/subscriptions", "organizations_url": "https://api.github.com/users/bennettandrews/orgs", "repos_url": "https://api.github.com/users/bennettandrews/repos", "events_url": "https://api.github.com/users/bennettandrews/events{/privacy}", "received_events_url": "https://api.github.com/users/bennettandrews/received_events", "type": "User", "site_admin": false}, "starred_repo": "apache/druid"}
{"starred_at": "2012-10-23T19:08:07Z", "user": {"login": "xwmx", "id": 1246, "node_id": "MDQ6VXNlcjEyNDY=", "avatar_url": "https://avatars.githubusercontent.com/u/1246?v=4", "gravatar_id": "", "url": "https://api.github.com/users/xwmx", "html_url": "https://github.com/xwmx", "followers_url": "https://api.github.com/users/xwmx/followers", "following_url": "https://api.github.com/users/xwmx/following{/other_user}", "gists_url": "https://api.github.com/users/xwmx/gists{/gist_id}", "starred_url": "https://api.github.com/users/xwmx/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/xwmx/subscriptions", "organizations_url": "https://api.github.com/users/xwmx/orgs", "repos_url": "https://api.github.com/users/xwmx/repos", "events_url": "https://api.github.com/users/xwmx/events{/privacy}", "received_events_url": "https://api.github.com/users/xwmx/received_events", "type": "User", "site_admin": false}, "starred_repo": "apache/druid"}
Upload the output file to Polaris and ingest only the starred_at, user["login"], user["id"], and starred_repo columns. (You will need to use JSON_VALUE to extract the nested fields.)
Create a data cube with default settings. By default, you will get an event count measure, but you can add your own filtered or computed measures if you want.
Naïve visualization
This first data model shows only the new stars for every point in time. This looks a bit confusing, but there is one interesting fact to be gleaned already:
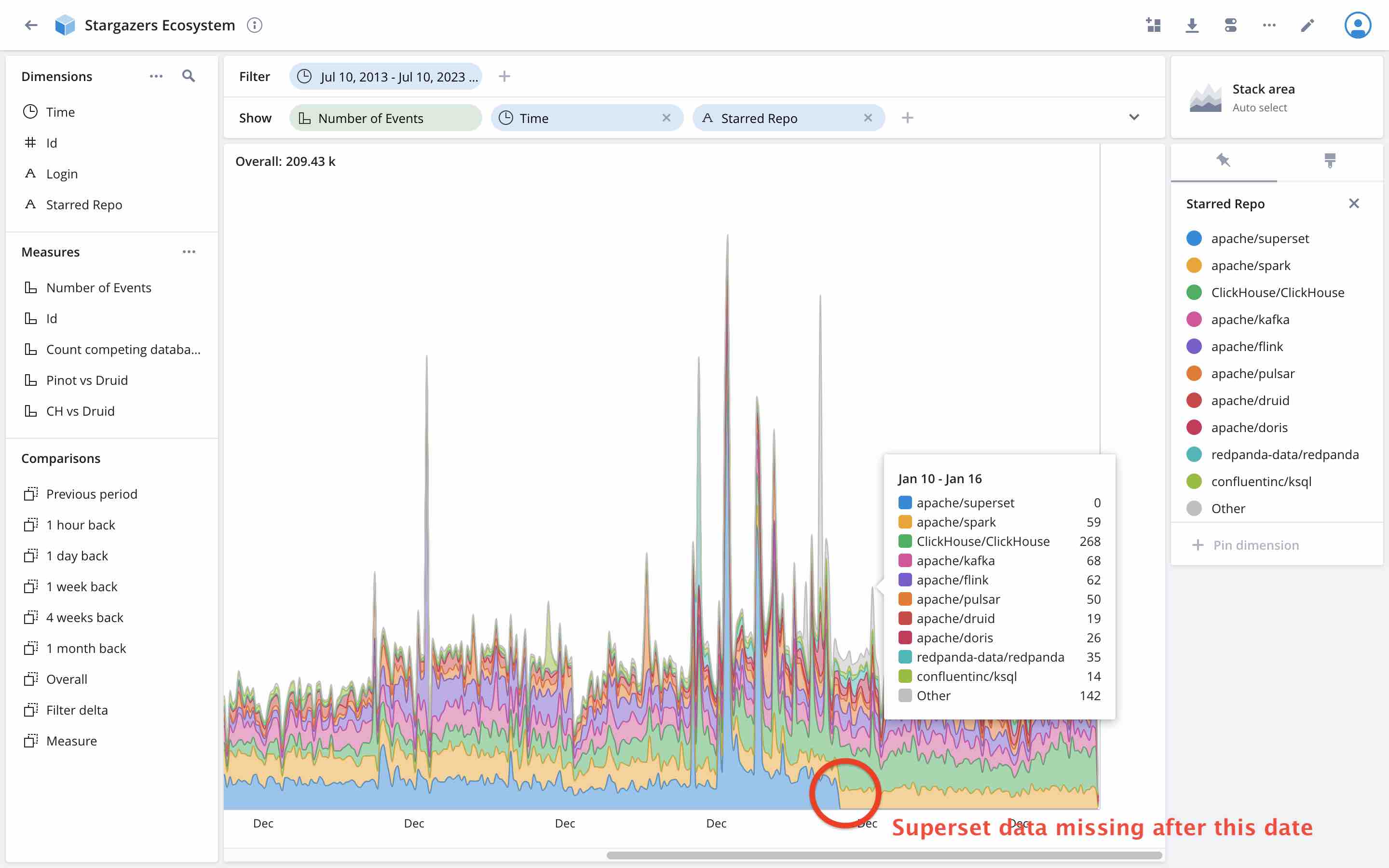
The new star data for the superset repository is gone after a certain date! Why is that?
Remember, we can only retrieve 40,000 stargazer records per repository. But Superset has more than 52,000 stars, so we cannot get them all.
This is a starting point, but what Will really wanted to see is the growth of stars over time. Something you would address using a window function and a BETWEEN CURRENT AND UNBOUND PRECEDING clause. But since window functions in Druid are not quite production ready yet, we have to use a different syntax to model these queries.
Let’s do this with monthly resolution so we can track the month over month growth curve for each repository.
First attempt at cumulative sums: self join
Last year, I wrote about emulating window functions in Druid SQL, and one of the techniques I used was to join a table with itself. Conveniently, we roll up by month before joining the data, so as to keep the intermediate result sets small. Since we are repeating the same query, let’s formulate it as a common table expression.
WITH cte AS (
SELECT DATE_TRUNC('MONTH', "__time") AS date_month, starred_repo, COUNT(*) AS count_monthly
FROM "stargazers-ecosystem"
GROUP BY 1, 2
)
SELECT
cte.date_month,
cte.starred_repo,
SUM(t2.count_monthly) AS sum_cume
FROM cte INNER JOIN cte t2 ON cte.starred_repo = t2.starred_repo
WHERE t2.date_month <= cte.date_month
GROUP BY 1, 2
ORDER BY 1, 2
The interesting measure in this data model is sum_cume: the sum of stars from all past up to the reference date, per repository. Let’s visualize this in Polaris over a time period of 10 years!
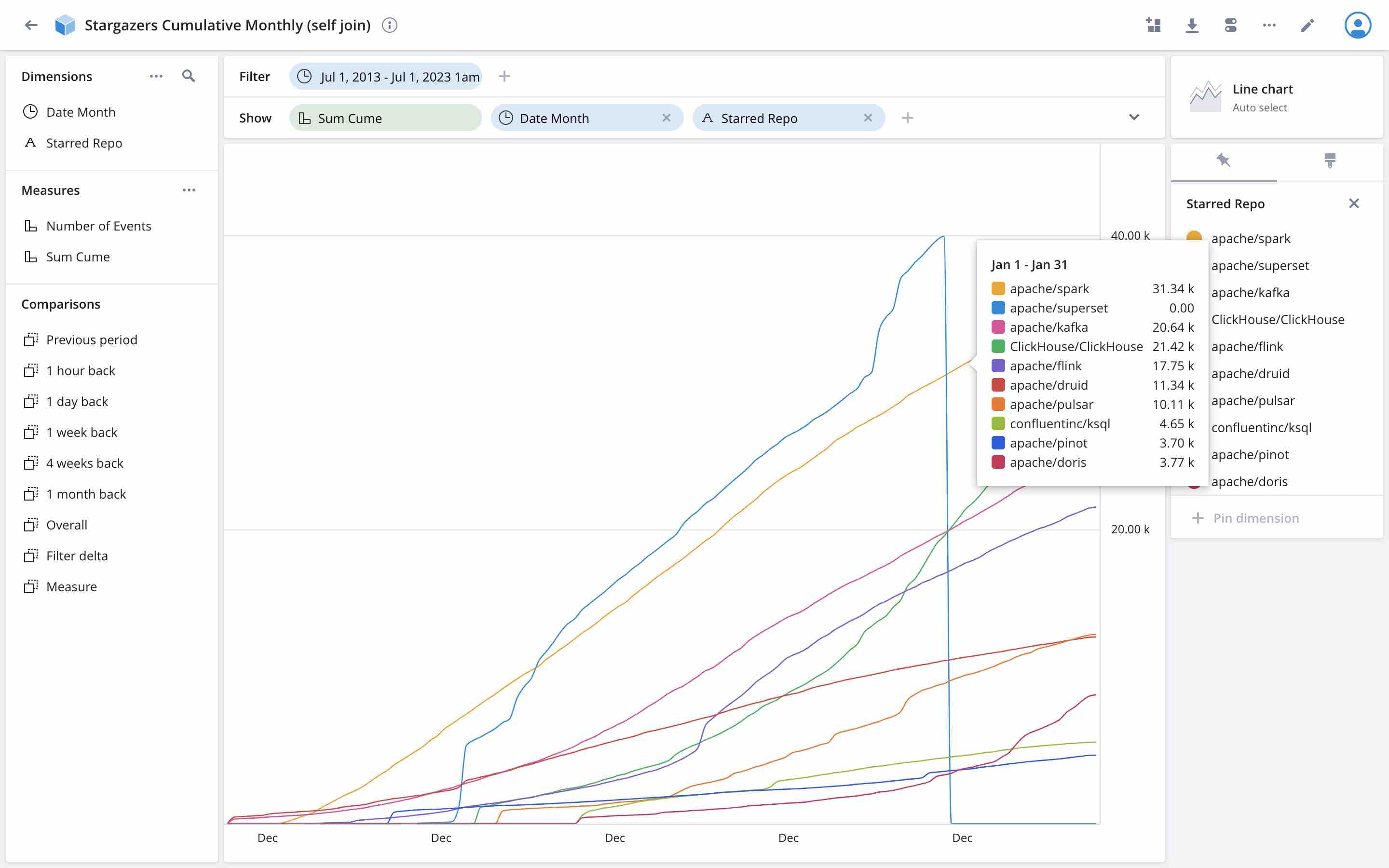
This is almost good, but did you notice how the superset line drops to zero? Why is that?
Well, you remember the 40k stars limit? Because we don’t get new entries after a certain date, the join has nothing to join against.
We have been hit by a well known problem in data modeling, factless facts. Generally, this problem of “holes” in the data is addressed by creating a canvas table that manages to get us a data point for each possible combination of dimension values, not only those that we have fact data for.
So let’s build up a calendar dimension instead, shall we
The straightforward approach to this task is to create a calendar dimension. Fortunately, since Druid 26, we have the ability to generate an array of equally spaced points in time (with DATE_EXPAND), and to transform such an array into a set of single value rows (with UNNEST). This is not quite a fully featured sequence generator, but it should work for our case.
Note that for all the sample queries you will need to set a query context flag to enable UNNEST:
{
"enableUnnest": true
}
Let’s try to fill out the time dimension with one record per month, from the minimum to maximum timestamp that is in the data:
SELECT t.dateByWeek
FROM (
SELECT
TIMESTAMP_TO_MILLIS(TIME_FLOOR(MIN(__time), 'P1M')) AS minDate,
TIMESTAMP_TO_MILLIS(TIME_CEIL(MAX(__time), 'P1M')) AS maxDate
FROM
"stargazers-ecosystem"
),
UNNEST(DATE_EXPAND(minDate, maxDate, 'P1M')) AS t(dateByWeek)
Unfortunately, the query fails. But it indicates clearly why:
Error: Unsupported operation
Cannot convert to Duration as this period contains months and months vary in length
So instead, let’s use the next largest interval that works with DATE_EXPAND, which is week - a week is always the same length -, then truncate to months, and deduplicate the values:
SELECT DISTINCT TIME_FLOOR(t.dateByWeek, 'P1M')
FROM (
SELECT
TIMESTAMP_TO_MILLIS(TIME_FLOOR(MIN(__time), 'P1M')) AS minDate,
TIMESTAMP_TO_MILLIS(TIME_CEIL(MAX(__time), 'P1M')) AS maxDate
FROM
"stargazers-ecosystem"
),
UNNEST(DATE_EXPAND(minDate, maxDate, 'P1W')) AS t(dateByWeek)
This works!
Join up against the fact data
Let’s try to join the calendar dimension against the fact data. We know already that we can’t have a “less than or equal” condition in the JOIN clause. So let’s try and write a Cartesian join with a WHERE clause that does the time windowing:
WITH
cte_calendar AS (
SELECT DISTINCT TIME_FLOOR(t.dateByWeek, 'P1M') AS date_month
FROM (
SELECT
TIMESTAMP_TO_MILLIS(TIME_FLOOR(MIN(__time), 'P1M')) AS minDate,
TIMESTAMP_TO_MILLIS(TIME_CEIL(MAX(__time), 'P1M')) AS maxDate
FROM
"stargazers-ecosystem"
),
UNNEST(DATE_EXPAND(minDate, maxDate, 'P1W')) AS t(dateByWeek)
),
cte_stars AS (
SELECT
DATE_TRUNC('MONTH', "__time") AS date_month,
starred_repo,
COUNT(*) AS count_monthly
FROM "stargazers-ecosystem"
GROUP BY 1, 2
)
SELECT
cte_calendar.date_month,
cte_stars.starred_repo,
SUM(cte_stars.count_monthly) AS sum_cume
FROM cte_calendar, cte_stars
WHERE cte_stars.date_month <= cte_calendar.date_month
GROUP BY 1, 2
ORDER BY 1, 2
Alas, this fails too - Druid’s query planner views this still as a JOIN with a non-equals condition, and refuses to plan it:
SQL requires a join with 'LESS_THAN_OR_EQUAL' condition that is not supported.
The message is clear, we need an equals join. Let’s do a workaround by adding starred_repo to the calendar canvas as well, so as to use it as a join key. So the canvas definition becomes a cross join between the monthly calendar we created above, and the list of all unique repositories:
SELECT
TIME_FLOOR(t.dateByWeek, 'P1M') AS date_month,
starred_repo
FROM (
SELECT
TIMESTAMP_TO_MILLIS(TIME_FLOOR(MIN(__time), 'P1M')) AS minDate,
TIMESTAMP_TO_MILLIS(TIME_CEIL(MAX(__time), 'P1M')) AS maxDate
FROM
"stargazers-ecosystem"
),
UNNEST(DATE_EXPAND(minDate, maxDate, 'P1W')) AS t(dateByWeek),
( SELECT DISTINCT starred_repo FROM "stargazers-ecosystem" )
GROUP BY 1, 2
Then define this as a CTE, join the facts on starred_repo, and tuck the unbound preceding condition away into a filtered metric:
WITH
cte_calendar AS (
SELECT
TIME_FLOOR(t.dateByWeek, 'P1M') AS date_month,
starred_repo
FROM (
SELECT
TIMESTAMP_TO_MILLIS(TIME_FLOOR(MIN(__time), 'P1M')) AS minDate,
TIMESTAMP_TO_MILLIS(TIME_CEIL(MAX(__time), 'P1M')) AS maxDate
FROM
"stargazers-ecosystem"
),
UNNEST(DATE_EXPAND(minDate, maxDate, 'P1W')) AS t(dateByWeek),
( SELECT DISTINCT starred_repo FROM "stargazers-ecosystem" )
GROUP BY 1, 2
),
cte_stars AS (
SELECT
DATE_TRUNC('MONTH', "__time") AS date_month,
starred_repo,
COUNT(*) AS count_monthly
FROM "stargazers-ecosystem"
GROUP BY 1, 2
)
SELECT
cte_calendar.date_month,
cte_stars.starred_repo,
SUM(cte_stars.count_monthly) FILTER(WHERE cte_stars.date_month <= cte_calendar.date_month) AS sum_cume
FROM cte_calendar INNER JOIN cte_stars ON cte_calendar.starred_repo = cte_stars.starred_repo
GROUP BY 1, 2
ORDER BY 1, 2
Use this query to define a cube in the Polaris GUI, and see the result:
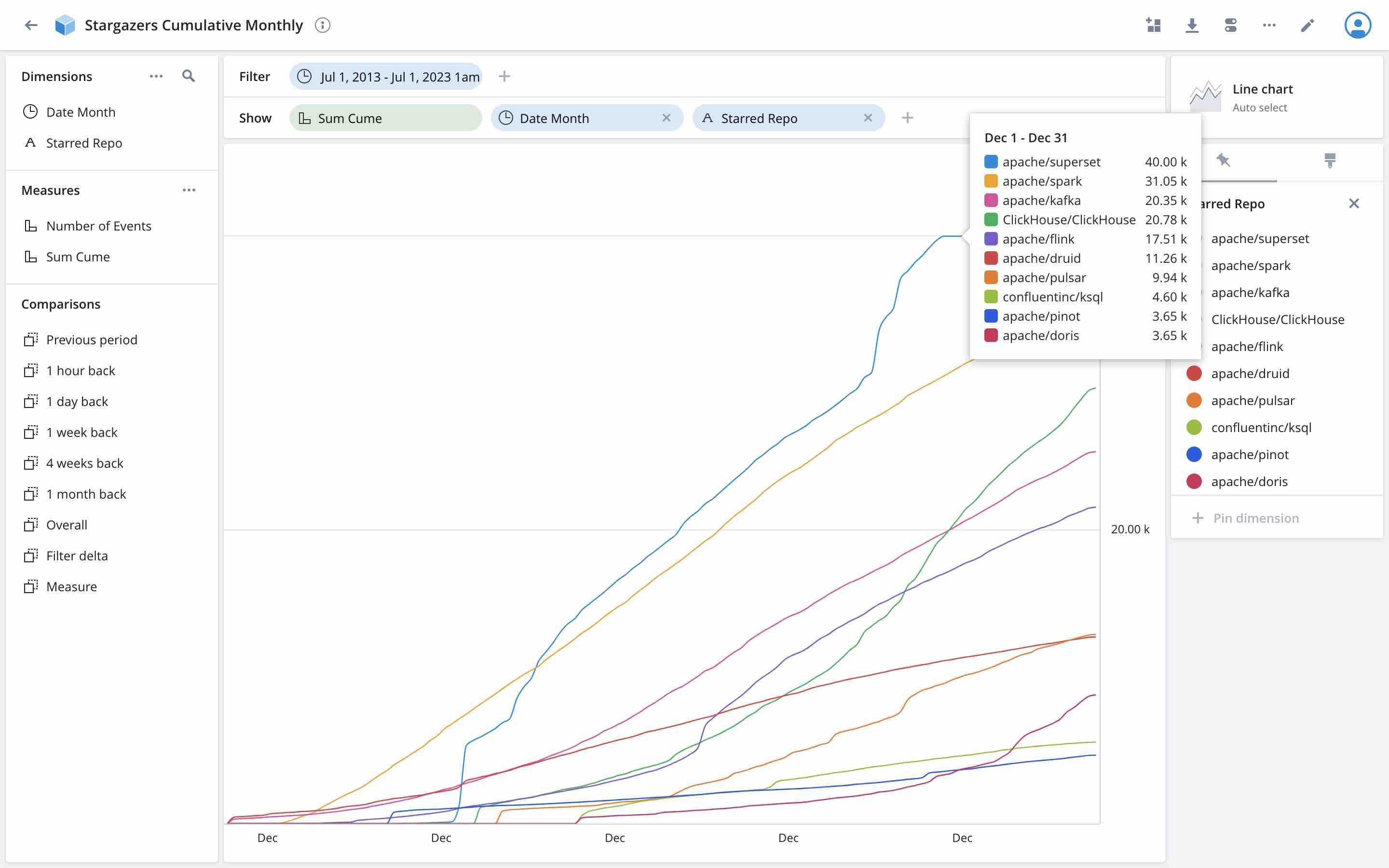
And, ceteris paribus, now the number of Superset stars maxes out at 40k but they don’t drop to zero!
Learnings
- The self join approach to cumulative sums fails when there are “holes” in the data (aka factless facts).
- The best approach to counter this is building an explicit calendar dimension.
DATE_EXPANDcan be used to build a calendar canvas but has some limitations. We showed how to work around those.- Also, we learned how we can work around the
JOINlimitation in Druid SQL by adding a synthetic join key to the calendar dimension and using a filtered metric.
“Ludwig_Richter-The_Star_Money-2-1862” (via Wikimedia Commons) is in the public domain in its country of origin and other countries and areas where the copyright term is the author’s life plus 100 years or fewer.
{kind=link}