New in Druid 26: Data Provenance Tracking with Kafka Headers, Automatically

I have previously written about processing and visualizing ADS-B flight radar data with Kafka and Druid. This time, let’s look at some new possibilities with ingesting those data in a bit more detail.
The story starts with a discussion within our DevRel team at Imply. Wouldn’t it be nice to have multiple flight radar receivers in different locations, and have them all produce data into the same Kafka topic (which lives in Confluent Cloud.) But then, one should also be able to add a unique client ID (and possibly other metadata) to each message. In short, we need data provenance tracking. This is indeed of practical use: in any serious enterprise use case, data lineage tracking is indisposable!
In Kafka, data lineage is tracked with message headers. These are basically key-value pairs that can be defined freely. Inside Kafka, the header values are coded as binary bytes - their meaning and encoding is governed by your data contract, something to keep in mind for later.
Druid has been able to ingest Kafka metadata for a while, and I have written about it before. But before version 26, you had to edit the ingestion spec manually to enable this feature. Now, it is supported by the Druid console, making things a lot easier. Let’s see how this works for our flight radar data!
In this tutorial, you will
- generate Kafka messages with headers from flight radar data
- ingest and model these data inside Druid
- and show how these data can be queried just like any other table column using Druid SQL.
For the tutorial, use at least Druid version 26.0. The Druid quickstart works fine.
Generating the data
In my blog, I’ve previously described how you can use a Raspberry Pi with a DVB-T stick to receive flight radar data. Let’s modify the Kafka connector script to generate ourselves some data with Kafka headers. kcat comes with a -H option to inject arbitrary headers into a Kafka message.
Edit the following script, entering a unique client ID of your choice and your geographical coordinates. Then follow the instructions in the blog above to install the script as a service on your Raspberry Pi.
#!/bin/bash
CC_BOOTSTRAP="<confluent cloud bootstrap server>"
CC_APIKEY="<api key>"
CC_SECRET="<secret>"
CC_SECURE="-X security.protocol=SASL_SSL -X sasl.mechanism=PLAIN -X sasl.username=${CC_APIKEY} -X sasl.password=${CC_SECRET}"
CLIENT_ID="<client id>"
LON="0.0"
LAT="0.0"
TOPIC_NAME="adsb-raw"
nc localhost 30003 \
| awk -F "," '{ print $5 "|" $0 }' \
| kafkacat -P \
-t ${TOPIC_NAME} \
-b ${CC_BOOTSTRAP} \
-H "ClientID=${CLIENT_ID}" \
-H "ReceiverLon=${LON}" \
-H "ReceiverLat=${LAT}" \
-K "|" \
${CC_SECURE}
This adds a Kafka key (the aircraft hex ID), a unique ID for the radar receiver, and also the receiver coordinates, as Kafka headers.
Ingesting the data
In Druid, create a Kafka connection. In my lab, I am using Confluent Cloud so I have to encode the credentials in the consumer properties as described in another of my blog posts. (If you are using a local, unsecured Kafka service, it is sufficient to enter the bootstrap server and Kafka topic.)
Note how the preview looks different from previous Druid versions:
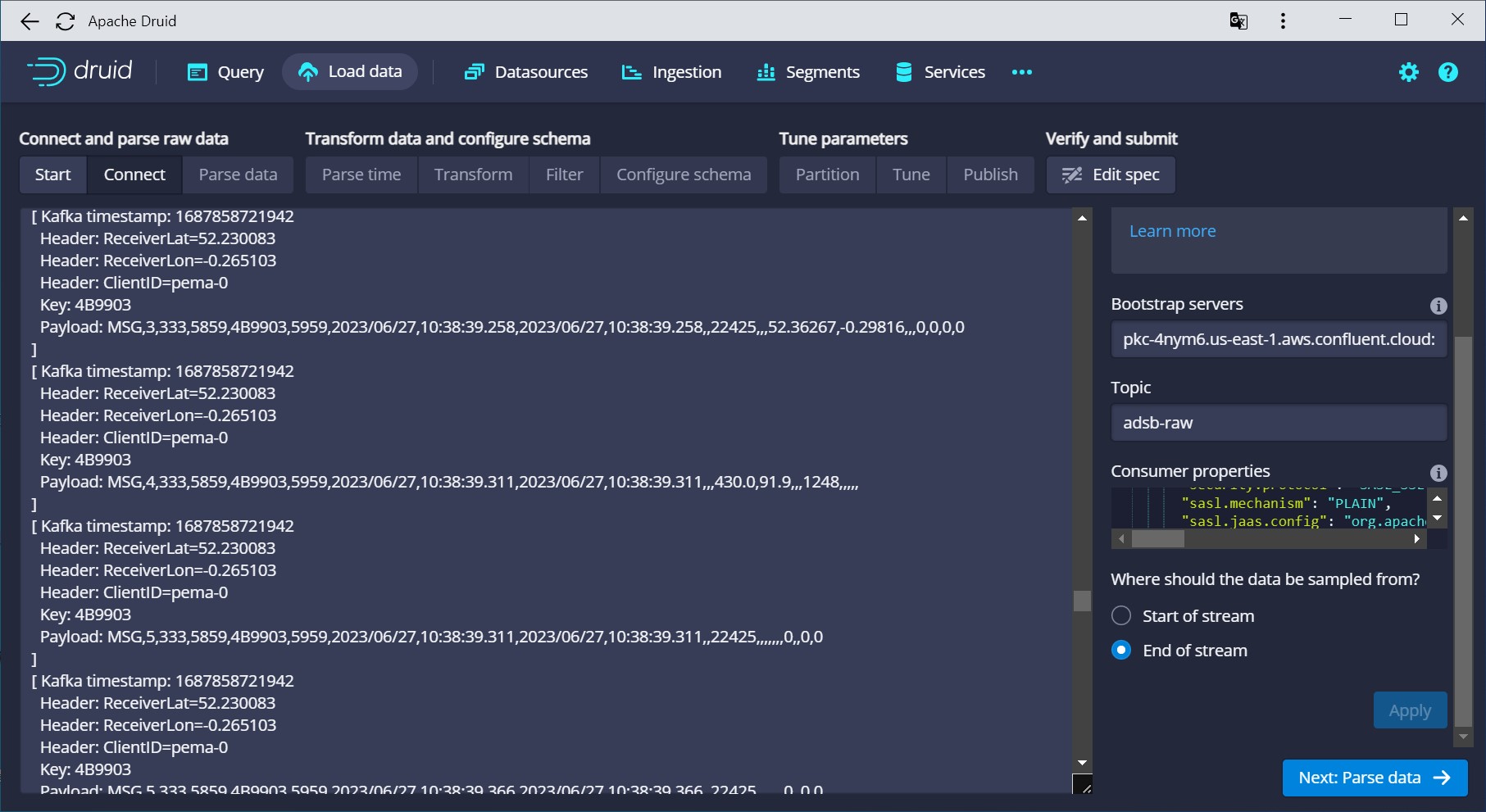
It now lists the Kafka metadata:
- timestamp
- key
- headers
along with the payload.
In the Parse data wizard, enter the column headers for the flight data:
MT,TT,SID,AID,Hex,FID,DMG,TMG,DML,TML,CS,Alt,GS,Trk,Lat,Lng,VR,Sq,Alrt,Emer,SPI,Gnd
Also make sure to enable the switch for parsing Kafka metadata (it should be on by default):
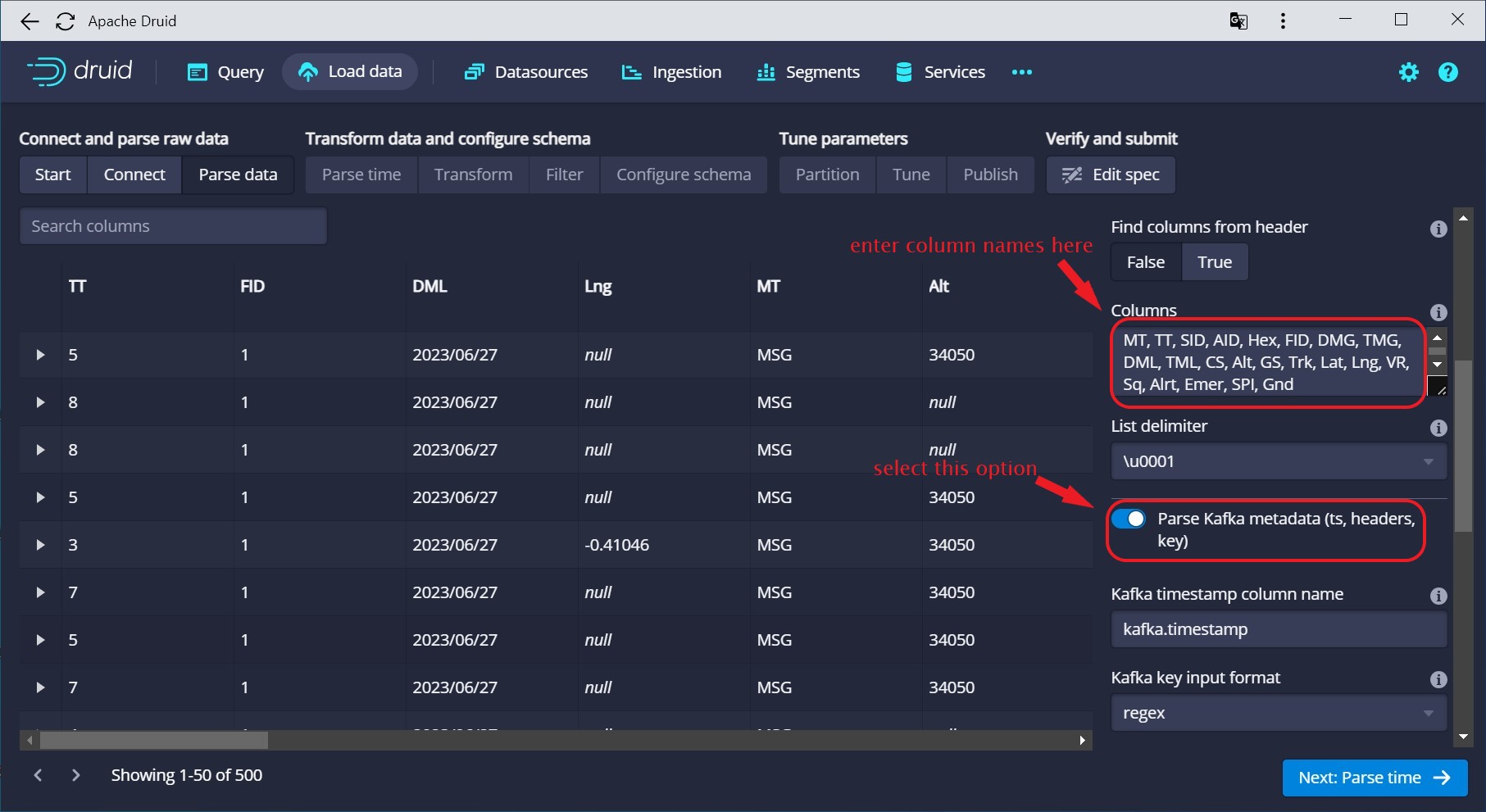
If you scroll down the right window pane, you will find a number of new options about handling the metadata.
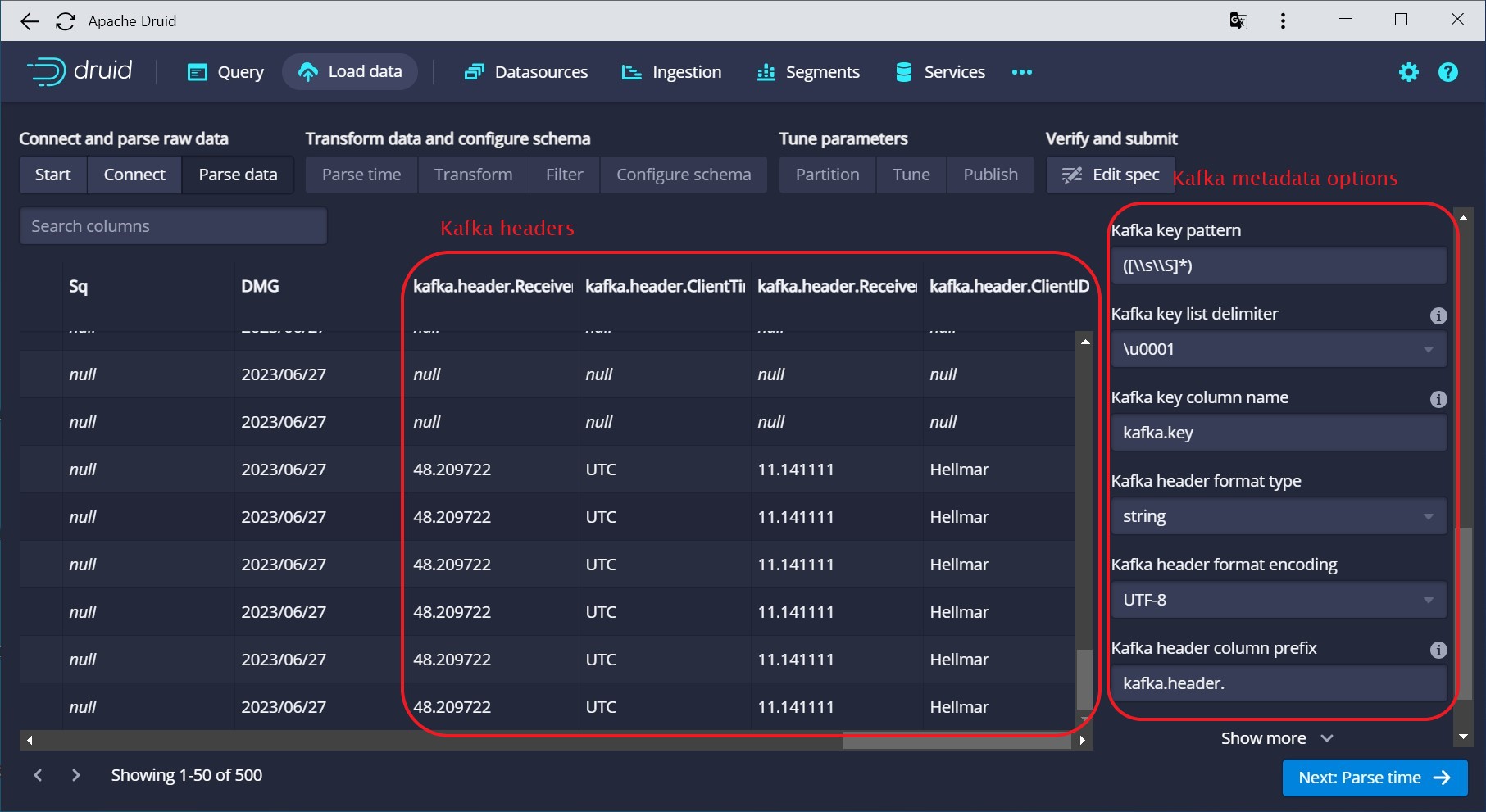
Here you specify how the key is parsed. (You could in theory have a structured key, because the key is parsed into an input format just like the payload. In practice, you will usually have a single string that can be parsed using a regular expression or a degenerate CSV parser.)
Moreover, this is where you define the prefixes to be used for the metadata in your final data model. And last but no least, you define how to decode the header values. In most cases, UTF-8 is a good choice, but it really depends on what your producer puts in at the other end.
The Kafka timestamp is automatically suggested as the primary Druid timestamp:
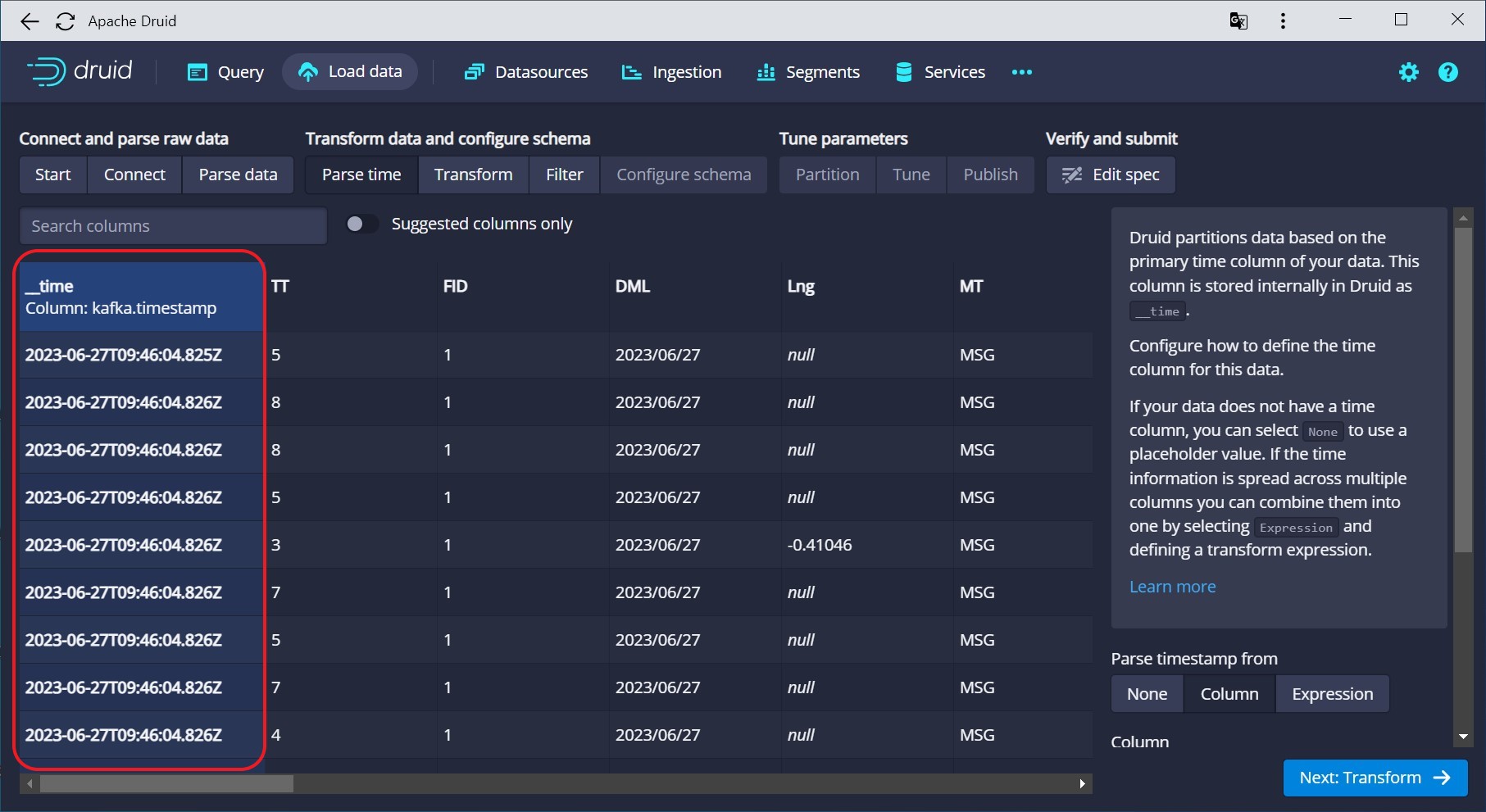
So, with a minimum configuration (as usual, you have to define your segment granularity and datasource name), you have your Kafka ingestion ready:
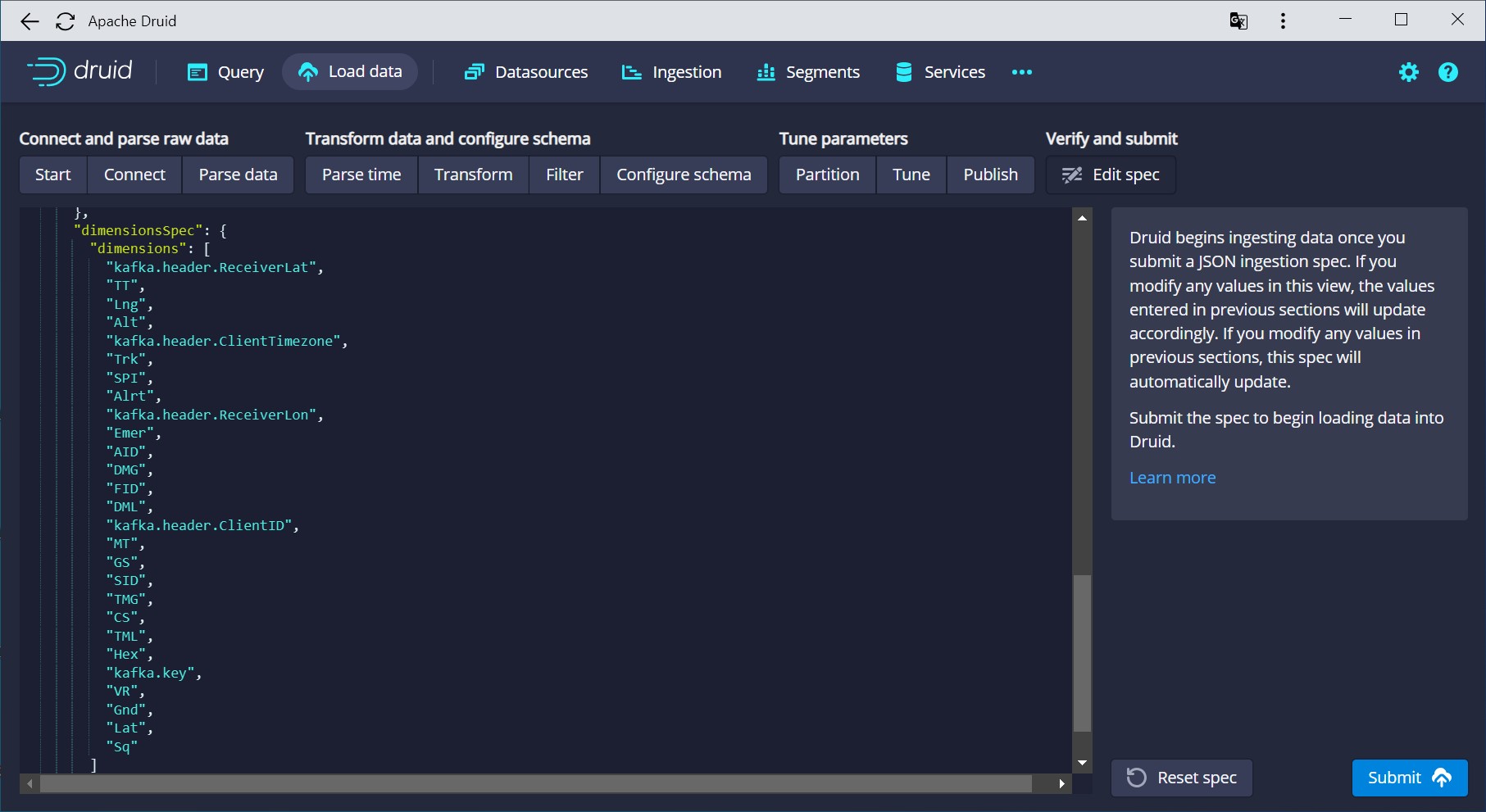
After submitting the spec, run a quick query to verify that indeed, the Kafka metadata has been parsed and ingested correctly:
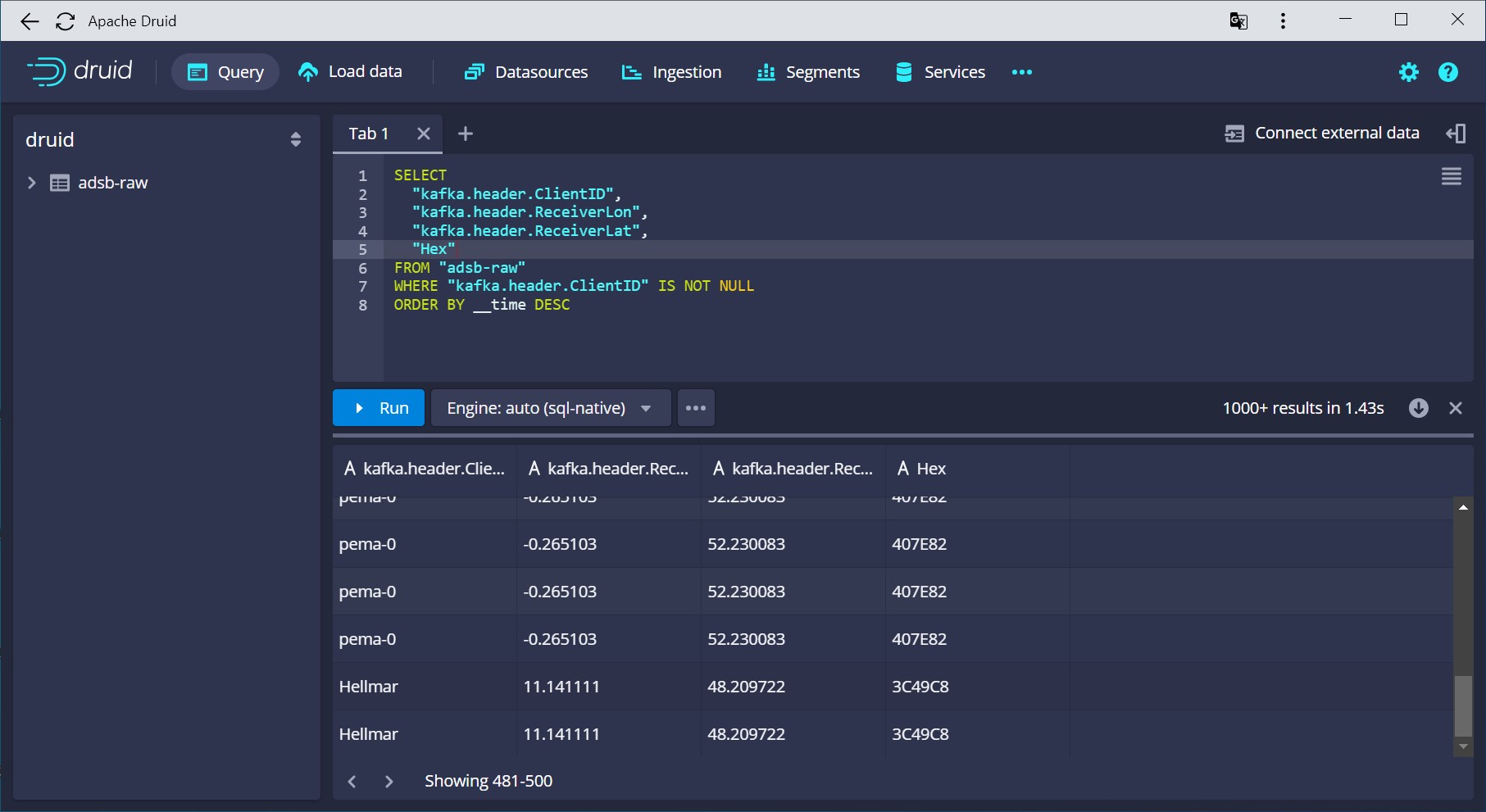
And that is how easily Kafka metadata goes into Apache Druid!
Conclusion
- Data lineage can be tracked with Kafka headers.
- Starting with Druid 26, Kafka metadata (timestamp, key, headers) are supported by the unified console wizard.
- With this, we can easily build a distributed flight data service using only one Kafka topic.
"Lufthansa Airbus A350 XWB D-AIXP arrives SFO L1060413" by wbaiv is licensed under CC BY-SA 2.0 ![]()
![]()
![]() .
.