Druid Sneak Peek: Schema Inference and Arrays
One of the strong points of Druid has always been built-in schema evolution. However, upon getting data of changing shape into Druid, you had two choices:
- either, specify each field with its type in the ingestion spec, which requires to know all the fields ahead of time
- or pick up whatever comes in using schemaless ingestion, with the downside that any dimension ingested that way would be interpreted as a string.
The good news is that this is going to change. Druid 26 is going to come with the ability to infer its schema completely from the input data, and even ingest structured data automatically.
Disclaimer: This tutorial uses undocumented functionality and unreleased code. This blog is neither endorsed by Imply nor by the Apache Druid PMC. It merely collects the results of personal experiments. The features described here might, in the final release, work differently, or not at all. In addition, the entire build, or execution, may fail. Your mileage may vary.
Druid 26 hasn’t been released yet, but you can build Druid from the master branch of the repository and try out the new features.
I am going to pick up the multi-value dimensions example from last week, but this time I want you to get an idea how these types of scenarios are going to be handled in the future. We are going to:
- ingest data using the new schema discovery feature
- ingest structured data into an SQL ARRAY
- show how
GROUP BYand lateral joins work with that array.
Ingestion: Schema Inference
We are using the ristorante dataset that you can find here, but with a little twist: On the Configure schema tab, uncheck Explicitly specify dimension list.
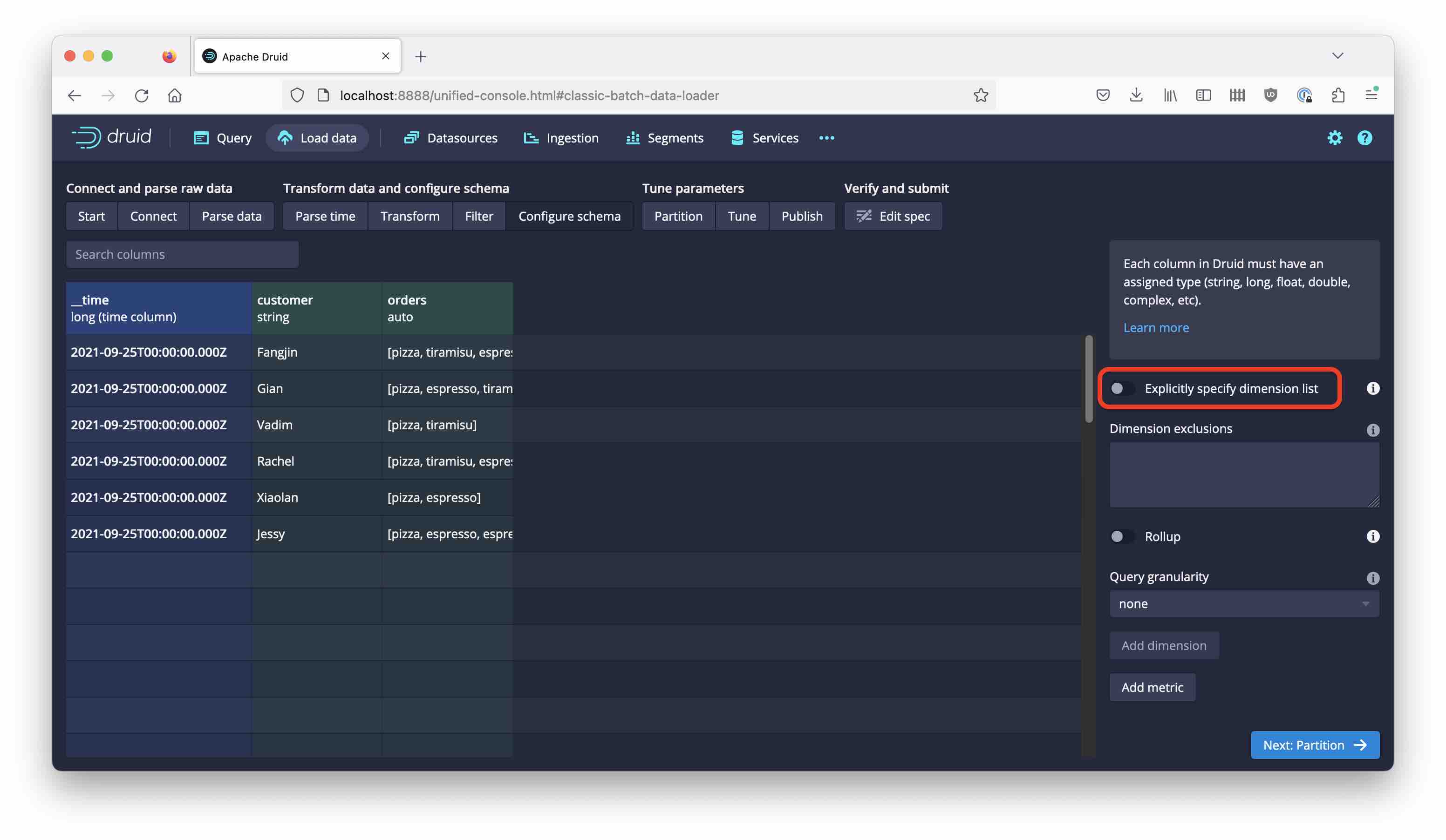
Confirm the warning dialog that pops up, and continue modeling the data. When you proceed to the Edit spec stage, you can see a new setting that slipped in:
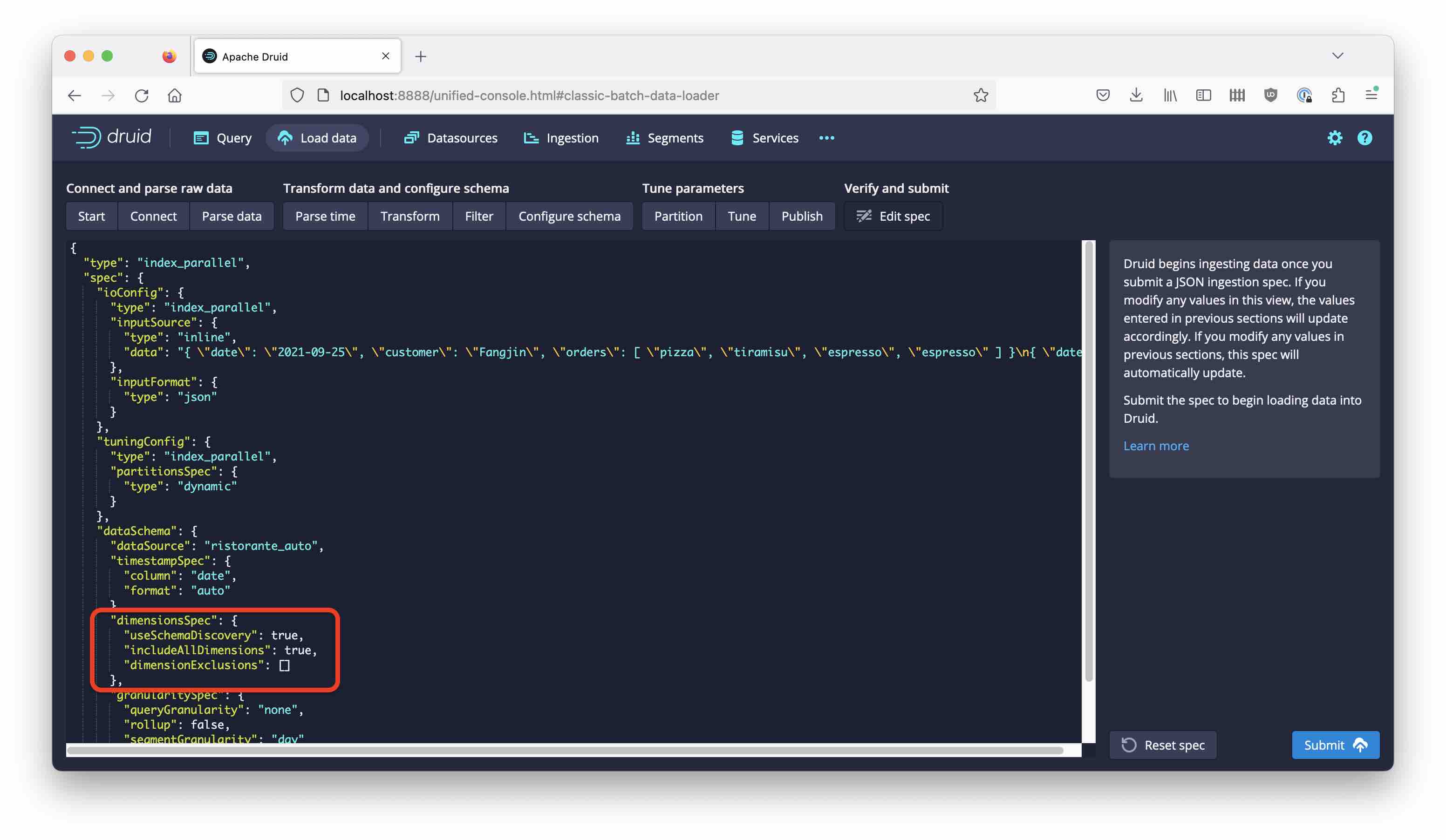
The dimensionsSpec has no dimension list now, but there is a new flag useSchemaDiscovery:
"dimensionsSpec": {
"useSchemaDiscovery": true,
"includeAllDimensions": true,
"dimensionExclusions": []
}
Querying the data
Let’s look at the resulting data with a simple SELECT * query:
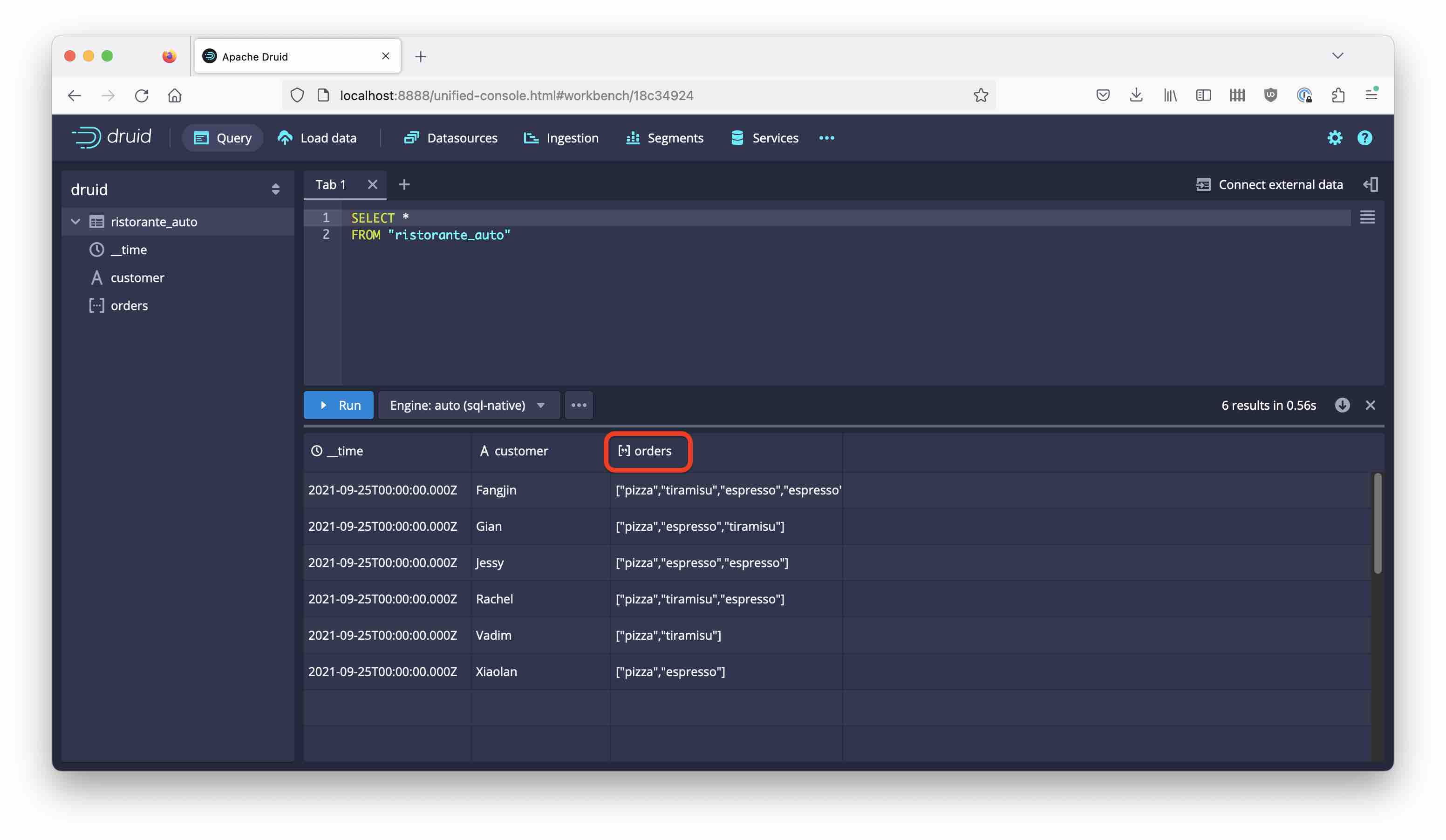
Notice how Druid has automatically detected that orders is an array of primitives (strings, in this case.) You recognize this by the symbol next to the columns name, which now looks like this: [··]. In older versions, this would have been either a multi-value string. But now, Druid has true ARRAY columns!
(In the more general case of nested objects, Druid would have generated a nested JSON column.)
In order to take the arrays apart, we can once again make use of the UNNEST function. This has to be enabled using a query context flag. In the console, use the Edit context function inside the query engine menu
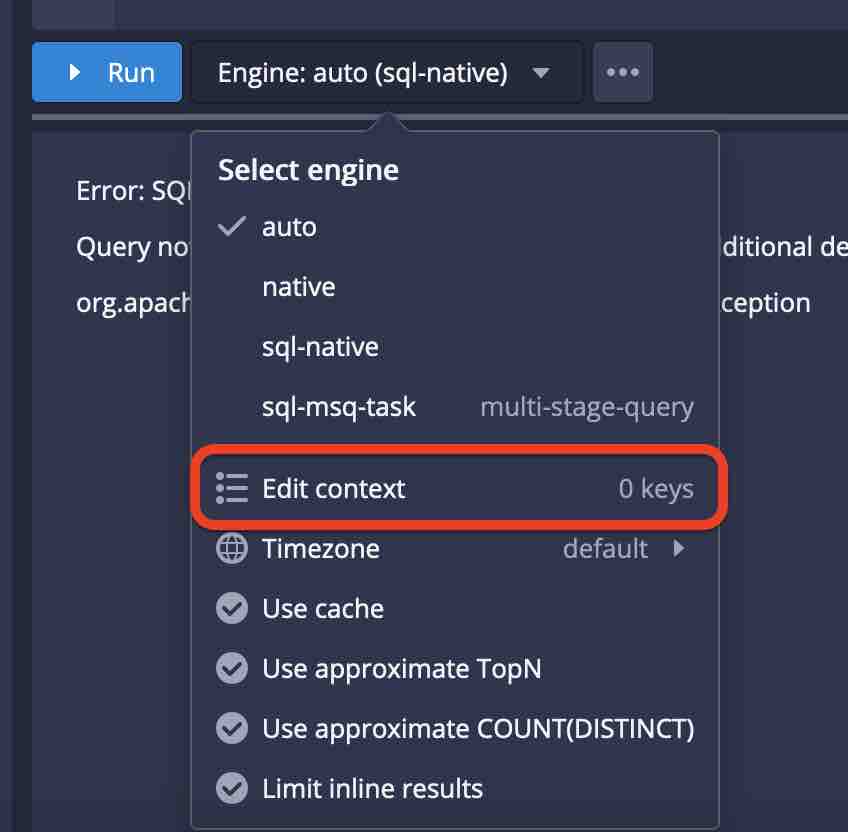
and enter the context:
{
"enableUnnest": true
}
In the REST API, you can pass the context directly.
Then, unnest and group the items:
SELECT
order_item,
COUNT(*) AS order_count
FROM "ristorante_auto", UNNEST(orders) AS t(order_item)
GROUP BY 1
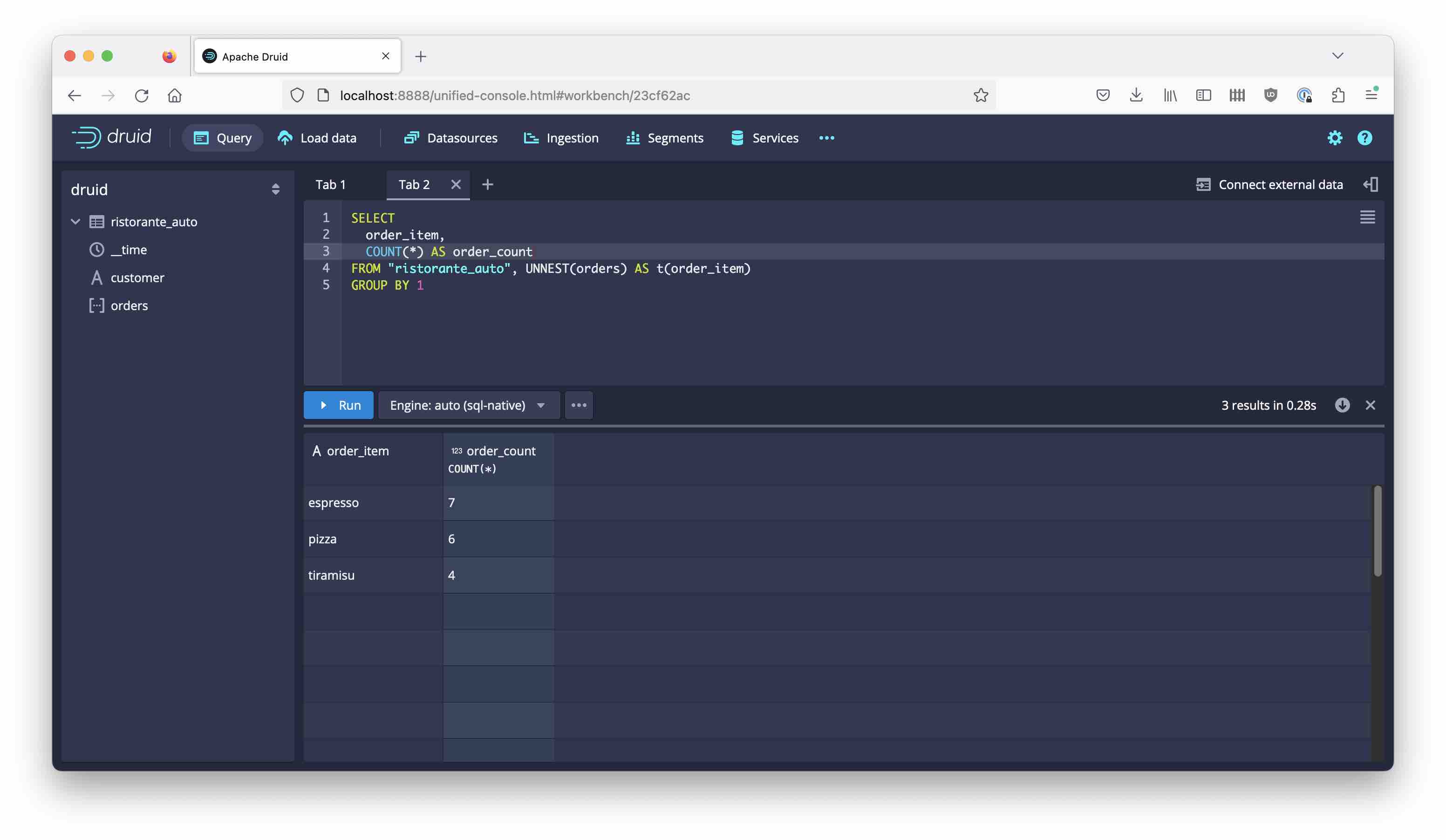
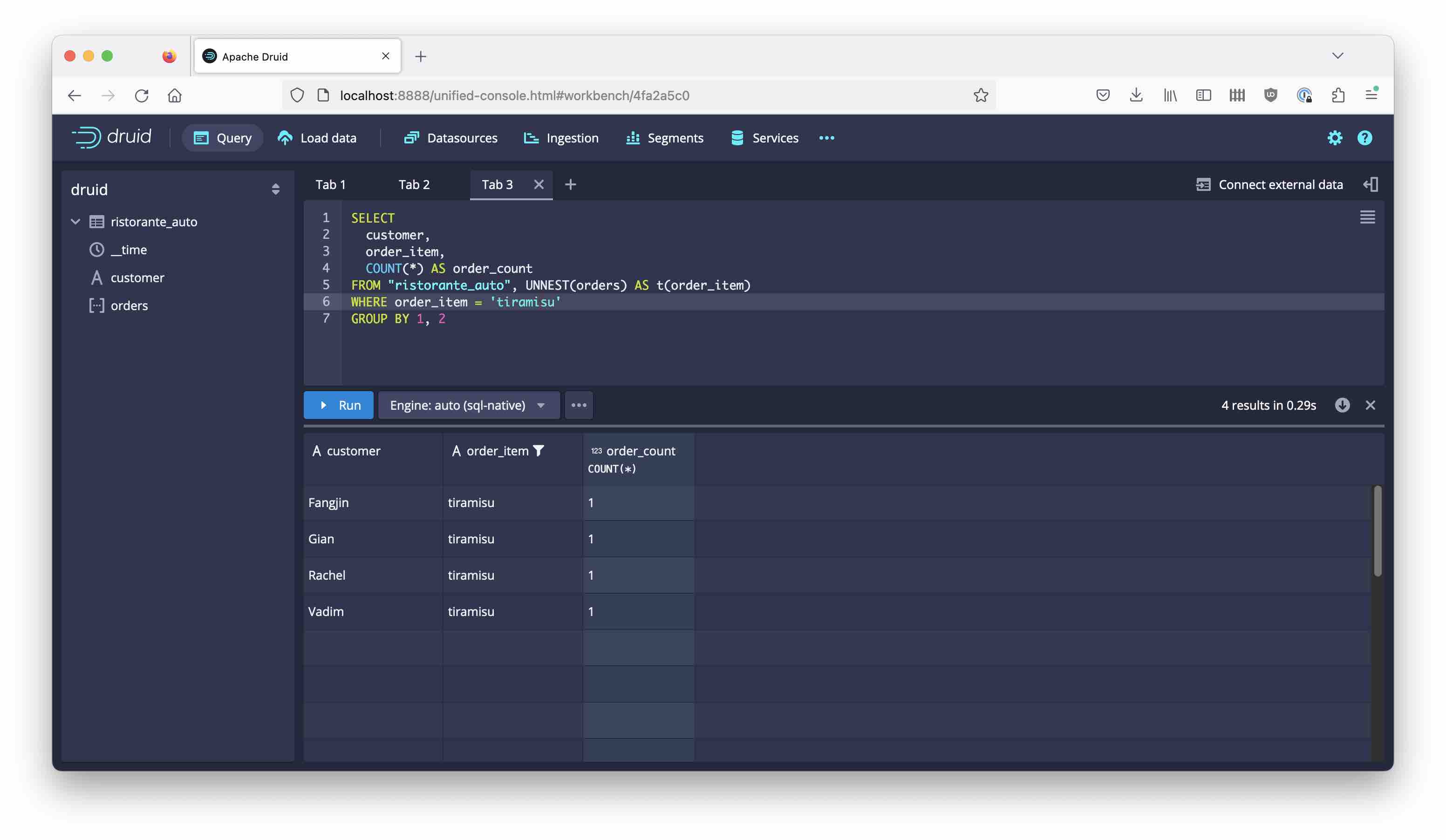
Once you have done this, you can filter by individual order items and you don’t have all the quirks that we talked about when doing multi-value dimensions:
SELECT
customer,
order_item,
COUNT(*) AS order_count
FROM "ristorante_auto", UNNEST(orders) AS t(order_item)
WHERE order_item = 'tiramisu'
GROUP BY 1, 2
Conclusion
- Druid can now do schema inference.
- It can automatically detect primitive types, but also nested objects and arrays of primitives.
- Typical Druid queries that would use multi-value dimensions in the past can now be done in a more standard way using array columns and
UNNEST.