Druid Sneak Peek: Timeseries Interpolation
Today I am going to look at another new Druid feature.
This is currently only available in Imply Enterprise which ships with all the featured discussed today, and comes with a free 30 day trial license. I sure hope it will come to open source Druid too.
In this tutorial, you will
- ingest a data sample and
- run a query to fill in missing values at regular time intervals, using a simple linear interpolation scheme.
Why is it cool? It uses
- the new
UNNESTfunction, which takes a collection and joins it laterally against the main table - the new
DATE_EXPANDfunction, which takes a start and end date and a step interval, and creates an array of timestamps, spaced by the step interval, between the start and end points - window functions, in our case the
LEADfunction to retrieve values from the succeeding row.
The data sample
Today’s data set is a simple time series of temperature measurements, which have been conducted every 6 hours:
date_start,temperature
2023-04-07T00:00:00Z,5
2023-04-07T06:00:00Z,8
2023-04-07T12:00:00Z,14
2023-04-07T18:00:00Z,12
2023-04-08T00:00:00Z,3
2023-04-08T06:00:00Z,6
2023-04-08T12:00:00Z,11
2023-04-08T18:00:00Z,5
We would like to fill the gaps, interpolating temperature values for each hour between the measurements.
Let’s ingest the data into Druid.
The ingestion spec is straightforward:
{
"type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "inline",
"data": "date_start,temperature\n2023-04-07T00:00:00Z,5\n2023-04-07T06:00:00Z,8\n2023-04-07T12:00:00Z,14\n2023-04-07T18:00:00Z,12\n2023-04-08T00:00:00Z,3\n2023-04-08T06:00:00Z,6\n2023-04-08T12:00:00Z,11\n2023-04-08T18:00:00Z,5"
},
"inputFormat": {
"type": "csv",
"findColumnsFromHeader": true
}
},
"tuningConfig": {
"type": "index_parallel",
"partitionsSpec": {
"type": "dynamic"
}
},
"dataSchema": {
"dataSource": "iot_data",
"timestampSpec": {
"column": "date_start",
"format": "iso"
},
"granularitySpec": {
"queryGranularity": "none",
"rollup": false,
"segmentGranularity": "month"
},
"dimensionsSpec": {
"dimensions": [
{
"type": "double",
"name": "temperature"
}
]
}
}
}
}
Query the data
Both the window functions and the UNNEST function are currently hidden behind context flags. Use the following query context:
{
"windowsAreForClosers": true,
"enableUnnest": true
}
With that, here is the query:
WITH cte AS (
SELECT
__time AS thisTime,
temperature,
LEAD(__time, 1) OVER (ORDER BY __time) nextTime,
LEAD(temperature, 1) OVER (ORDER BY __time) nextTemperature
FROM "iot_data"
GROUP BY 1,2
)
SELECT
timeByHour,
CASE (TIMESTAMP_TO_MILLIS(nextTime) - TIMESTAMP_TO_MILLIS(thisTime))
WHEN 0 THEN temperature
ELSE ((TIMESTAMP_TO_MILLIS(nextTime) - TIMESTAMP_TO_MILLIS(timeByHour)) * temperature
+ (TIMESTAMP_TO_MILLIS(timeByHour) - TIMESTAMP_TO_MILLIS(thisTime)) * nextTemperature)
/ (TIMESTAMP_TO_MILLIS(nextTime) - TIMESTAMP_TO_MILLIS(thisTime))
END interpTemp
FROM cte, UNNEST(DATE_EXPAND(TIMESTAMP_TO_MILLIS(thisTime), TIMESTAMP_TO_MILLIS(NVL(nextTime, thisTime)), 'PT1H')) AS t(timeByHour)
WHERE timeByHour <> nextTime
It uses the common table expression technique that already came in handy last time.
Here is the result:
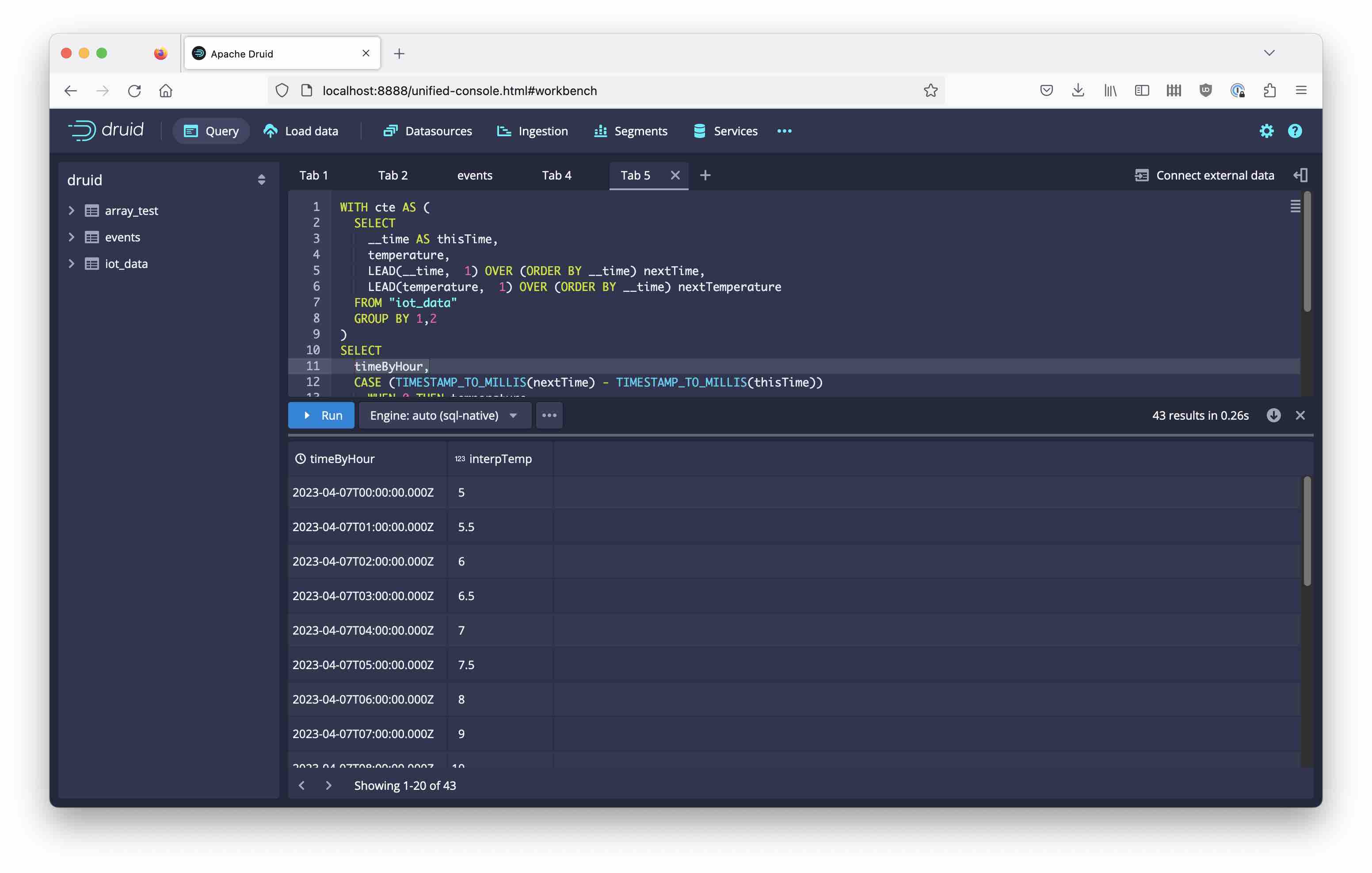
As you can see in the last column, the values have been neatly interpolated.
Side Quests
It is worth looking at some details of the query. Some of these are just common, others are due to quirks in the Druid query engine.
The date expansion
DATE_EXPAND(TIMESTAMP_TO_MILLIS(thisTime), TIMESTAMP_TO_MILLIS(NVL(nextTime, thisTime)), 'PT1H')
The general syntax would be DATE_EXPAND(from, to, interval). But since we are using LEAD() to get the to value, the last row will have null in that place. Unfortunately, DATE_EXPAND doesn’t handle that situation well and the query fails. That’s why in the case of a null value, I use the row time instead, generating only one row.
WHERE timeByHour <> nextTime
DATE_EXPAND considers its time interval as left and right inclusive. This means that the end values will be duplicated with the start values of the next interval. The WHERE clause filters out the duplicates.
The interpolation
CASE (TIMESTAMP_TO_MILLIS(nextTime) - TIMESTAMP_TO_MILLIS(thisTime))
WHEN 0 THEN temperature ...
The general formula for linear interpolation has to divide by the total time range. If this is 0, just use the one value that is provided. This comes from the corner case treatment above.
Conclusion
Druid’s timeseries capabilities are ever expanding.
- With
DATE_EXPANDandUNNEST, it is possible to generate evenly spaced time series. - Using window functions and standard interpolation algorithms, this can be used to fill in missing values.
- Currently this is only available in Imply’s release.
"Hot & Cold" by astronomy_blog is licensed under CC BY-NC-SA 2.0
![]()
![]()
![]()
![]() .
.