Ingesting Data Sketches into Apache Druid
Data Sketches are a powerful way to get fast approximations for a bunch of measures that are very expensive to compute precisely. This includes distinct counts and quantiles.
While data sketches can be computed directly within Druid, some of my customers prefer to roll up the data and compute the sketches in the preprocessing stage. Today, I am going to look at a few scenarios around ingesting these sketches.
This is a sneak peek into Druid 25 functionality. In order to use the new functions, you can (as of the time of writing) build the current release candidate:
git clone https://github.com/apache/druid.git
cd druid
git checkout druid-25.0.0-rc1
mvn clean install -Pdist -DskipTests
Then follow the instructions to locate and install the tarball.
Disclaimer: This tutorial uses undocumented functionality. This blog is neither endorsed by Imply nor by the Apache Druid PMC. It merely collects the results of personal experiments. The features described here might, in the final release, work differently, or not at all. Your mileage may vary.
Generating the data sample
First, let’s generate our data set that has precomputed data sketches. I am going to use Druid for this; in a real project, you might use Spark or whatever preprocessing you have in place.
I am using the Wikipedia sample data that comes with each Druid version. This is one day’s worth of Wikipedia edits, which for the purpose of this tutorial, I will roll up by hour. I am interested in unique users by hour and channel, and I will model those both as HLL sketches and theta sketches. Here is the ingestion spec for this:
{
"type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "http",
"uris": [
"https://druid.apache.org/data/wikipedia.json.gz"
]
},
"inputFormat": {
"type": "json"
}
},
"dataSchema": {
"granularitySpec": {
"segmentGranularity": "day",
"queryGranularity": "hour",
"rollup": true
},
"dataSource": "wikipedia-rollup-00",
"timestampSpec": {
"column": "timestamp",
"format": "iso"
},
"dimensionsSpec": {
"dimensions": [
"channel"
]
},
"metricsSpec": [
{
"name": "__count",
"type": "count"
},
{
"name": "theta_user",
"type": "thetaSketch",
"fieldName": "user"
},
{
"type": "HLLSketchBuild",
"name": "hll_user",
"fieldName": "user"
}
]
},
"tuningConfig": {
"type": "index_parallel",
"partitionsSpec": {
"type": "range",
"partitionDimensions": [
"channel"
],
"targetRowsPerSegment": 5000000
},
"forceGuaranteedRollup": true
}
}
}
For reference, run a GROUP BY query in the console:
SELECT
__time,
SUM(__count) AS numRows,
HLL_SKETCH_ESTIMATE(DS_HLL(hll_user)) AS uniqueUsersHLL,
THETA_SKETCH_ESTIMATE(DS_THETA(theta_user)) AS uniqueUsersTheta
FROM "wikipedia-rollup-00"
GROUP BY 1
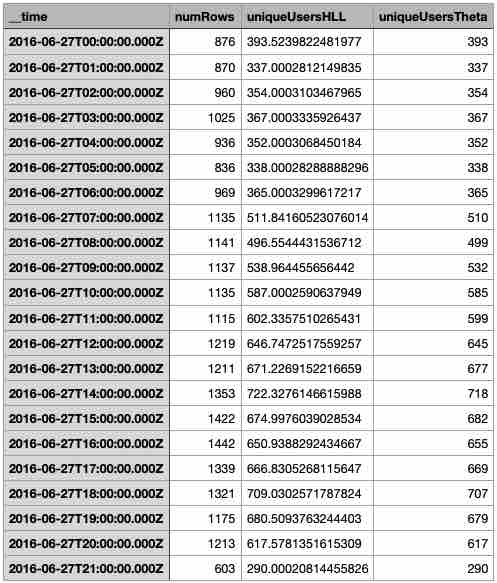
Let’s export the full data into a newline delimited JSON file. This can be done using Druid’s SQL API. There are a few caveats:
- I am putting an alias on the
__timecolumn. The name__timeis reserved in Druid and we will get into trouble if it occurs in the input data. - By default, Druid returns the result set in a JSON array. For playing back the data, we need newline delimited JSON. A quick incantation of
jqfixes this. - If you select any sketch field in a query, it is automatically converted into a base-64 encoded string and surrounded with an extra set of double quotes. These are then escaped as
'\"'in the result set. The quick and dirty way to remove those is withsed.
Here is the complete command line:
curl -XPOST -H "Content-Type: application/json" http://localhost:8888/druid/v2/sql/ -d'{ "query": "SELECT __time AS t_hour, channel, __count, hll_user, theta_user FROM \"wikipedia-rollup-00\"" }' | jq -c '.[]' | sed -e 's/\\\"//g' >wikipedia-rollup-00.json
Ingesting the sketches back into Druid
In order to convert the base-64 strings back into binary sketches, we need to employ a few special options.
Here is the ingestion spec:
{
"type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "local",
"baseDir": "/Users/hellmarbecker/meetup-talks/talaria-sketches",
"filter": "wikipedia-rollup-00.json"
},
"inputFormat": {
"type": "json"
}
},
"tuningConfig": {
"type": "index_parallel",
"partitionsSpec": {
"type": "hashed"
},
"forceGuaranteedRollup": true
},
"dataSchema": {
"dataSource": "wikipedia-rollup-01",
"timestampSpec": {
"column": "t_hour",
"format": "auto"
},
"transformSpec": {},
"dimensionsSpec": {
"dimensions": [
"channel"
]
},
"granularitySpec": {
"queryGranularity": "hour",
"rollup": true,
"segmentGranularity": "day"
},
"metricsSpec": [
{
"name": "__count",
"type": "longSum",
"fieldName": "__count"
},
{
"name": "theta_user",
"type": "thetaSketch",
"fieldName": "theta_user",
"isInputThetaSketch": true
},
{
"name": "hll_user",
"type": "HLLSketchMerge",
"fieldName": "hll_user"
}
]
}
}
}
Note how the fact that we are ingesting pregenerated sketches is expressed differently, depending on the type of sketch. For HLL, we specify type HLLSketchMerge, but for theta sketches it is an extra flag isInputThetaSketch that we have to set.
Run the same query as before but against the new datasource:
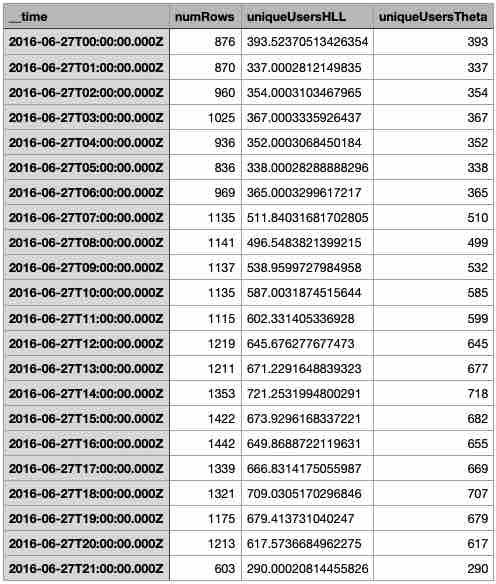
Within rounding error, the resulting table gives the same query results as the original. Nice.
Doing it with SQL Ingestion
SQL based ingestion was added in Druid 24. There’s also a wizard in the Query window that can convert a JSON ingestion spec into equivalent SQL. It is a bit hidden near the query options:
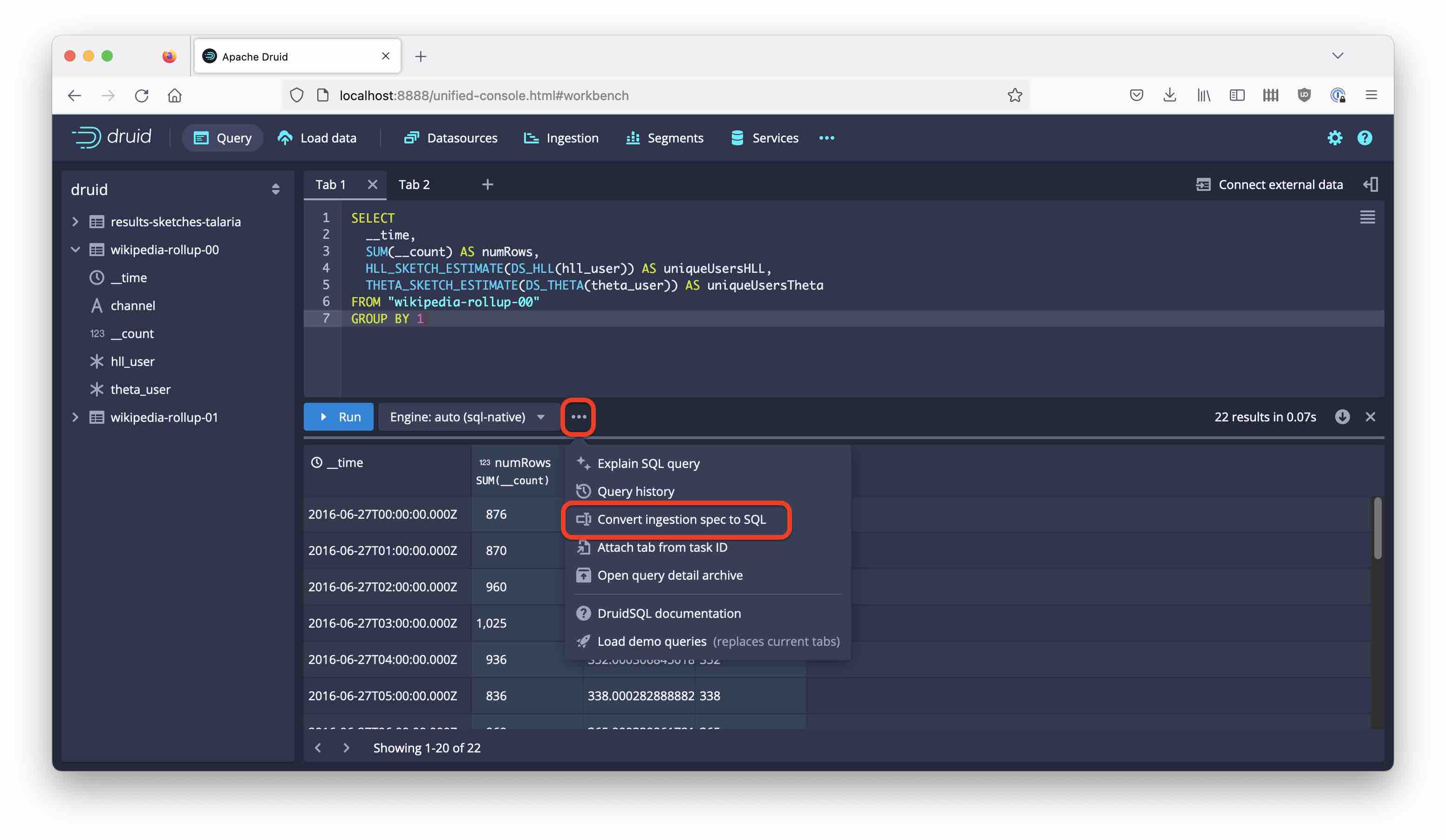
Let’s see where that gets us. This is the autogenerated SQL - I merely changed the name of the target datasource:
-- This SQL query was auto generated from an ingestion spec
REPLACE INTO "wikipedia-rollup-02" OVERWRITE ALL
WITH "source" AS (SELECT * FROM TABLE(
EXTERN(
'{"type":"local","baseDir":"/Users/hellmarbecker/meetup-talks/talaria-sketches","filter":"wikipedia-rollup-00.json"}',
'{"type":"json"}',
'[{"name":"t_hour","type":"string"},{"name":"channel","type":"string"},{"name":"__count","type":"long"},{"name":"theta_user","type":"string"},{"name":"hll_user","type":"string"}]'
)
))
SELECT
TIME_FLOOR(CASE WHEN CAST("t_hour" AS BIGINT) > 0 THEN MILLIS_TO_TIMESTAMP(CAST("t_hour" AS BIGINT)) ELSE TIME_PARSE("t_hour") END, 'PT1H') AS __time,
"channel",
SUM("__count") AS "__count",
APPROX_COUNT_DISTINCT_DS_THETA("theta_user") AS "theta_user",
APPROX_COUNT_DISTINCT_DS_HLL("hll_user") AS "hll_user"
FROM "source"
GROUP BY 1, 2
PARTITIONED BY DAY
If you run the ingestion from the Query window, you can monitor the progress through the stages:
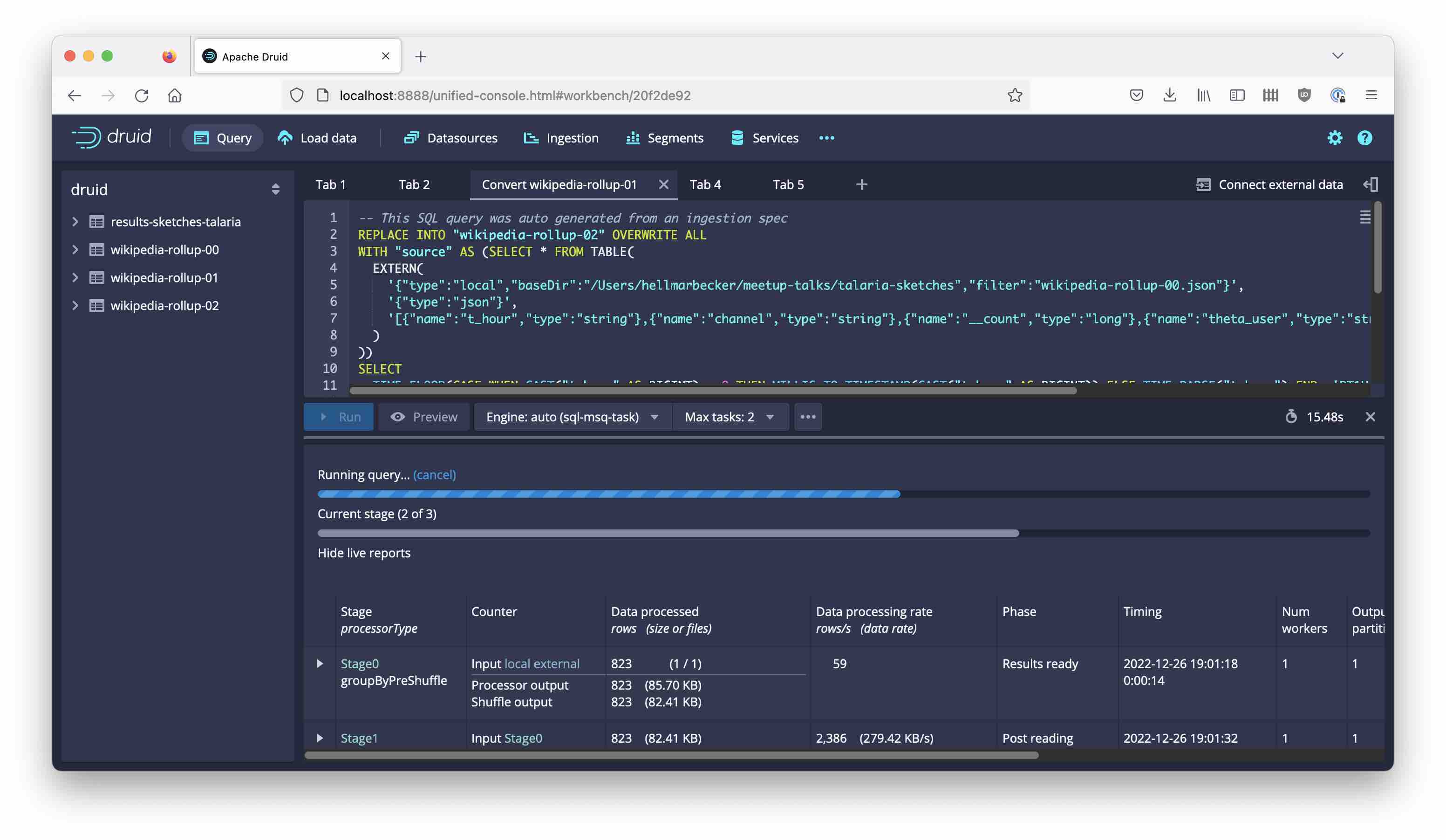
After a few seconds, the process is finished. Let’s check the result again:
SELECT
__time,
SUM(__count) AS numRows,
HLL_SKETCH_ESTIMATE(DS_HLL(hll_user)) AS uniqueUsersHLL,
THETA_SKETCH_ESTIMATE(DS_THETA(theta_user)) AS uniqueUsersTheta
FROM "wikipedia-rollup-02"
GROUP BY 1
And here is the result:
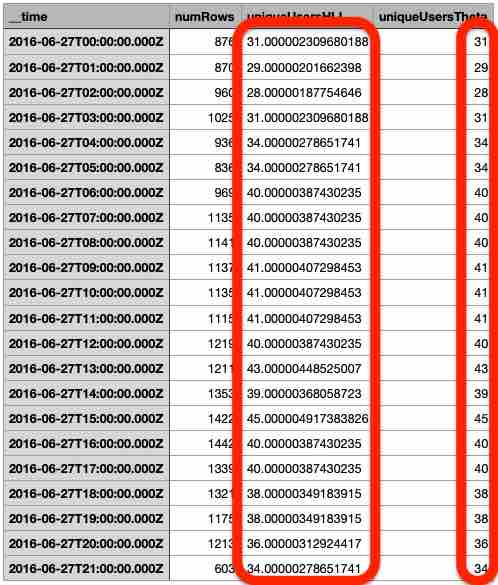
This does not look right. What happened here?
Fixing the SQL ingestion
It turns out that in the process of converting to SQL, the “magic” of sketches got dropped. The SQL ingestion engine processes the base-64 strings just like any other strings. This time we have been counting the number of distinct sketch strings rather than the distinct objects represented by the sketches!
To rescue the situation, we have to use the undocumented COMPLEX_DECODE_BASE64 function. This function takes as its first argument the type of object we want to convert into, such as 'thetaSketch' or 'HLLSketch'; the second argument is the field or expression that we want to convert from base-64 to complex object.
So, here’s the plan: apply COMPLEX_DECODE_BASE64 to our sketch representations, and then slam a sketch aggregator on top because we are dealing with a rolled up measure.
This SQL ingestion does the trick:
REPLACE INTO "wikipedia-rollup-03" OVERWRITE ALL
WITH "source" AS (SELECT * FROM TABLE(
EXTERN(
'{"type":"local","baseDir":"/Users/hellmarbecker/meetup-talks/talaria-sketches","filter":"wikipedia-rollup-00.json"}',
'{"type":"json"}',
'[{"name":"t_hour","type":"string"},{"name":"channel","type":"string"},{"name":"__count","type":"long"},{"name":"theta_user","type":"string"},{"name":"hll_user","type":"string"}]'
)
))
SELECT
TIME_FLOOR(CASE WHEN CAST("t_hour" AS BIGINT) > 0 THEN MILLIS_TO_TIMESTAMP(CAST("t_hour" AS BIGINT)) ELSE TIME_PARSE("t_hour") END, 'PT1H') AS __time,
"channel",
SUM("__count") AS "__count",
DS_THETA(COMPLEX_DECODE_BASE64('thetaSketch', "theta_user")) AS "theta_user",
DS_HLL(COMPLEX_DECODE_BASE64('HLLSketch', "hll_user")) AS "hll_user"
FROM "source"
GROUP BY 1, 2
PARTITIONED BY DAY
You can easily verify that the datasource, populated this way, gives the correct results again!
The same trick works also in Imply Polaris, where fields are defined using SQL expressions in table ingestion.
Conclusion
- Pre-computed data sketches can be ingested into Druid and Druid can easily work with them.
- With JSON based ingestion, some extra options are needed.
- With SQL ingestion, use the undocumented
COMPLEX_DECODE_BASE64function to process existing sketches.