Processing Nested JSON Data and Kafka Metadata in Apache Druid

Druid 24.0 brought the ability to ingest and store nested (JSON) columns directly. In most cases, this would eliminate the need to flatten JSON data during ingestion.
Inspired by real world experience, I am showing how to work with JSON columns and Kafka timestamps in the same ingestion spec, and how column flattening and nested columns complement each other to enable this use case.
This tutorial uses Aiven’s pizza simulator. I assume that you are running Kafka locally in a single broker configuration, and that you are producing data to a topic named pizza.
The tutorial uses Druid 24.0 quickstart.
The Data
The data generator simulates pizza orders. Here’s a sample record:
{
"id": 14492,
"shop": "Mammamia Pizza",
"name": "Juan Gonzalez",
"phoneNumber": "5474461494",
"address": "462 Williams Tunnel Apt. 424\nNicoletown, WY 02258",
"pizzas": [
{
"pizzaName": "Mari & Monti",
"additionalToppings": [
"🍅 tomato",
"🧅 onion"
]
},
{
"pizzaName": "Diavola",
"additionalToppings": []
},
{
"pizzaName": "Salami",
"additionalToppings": [
"🧄 garlic",
"🍅 tomato",
"🧅 onion",
"🥚 egg"
]
},
{
"pizzaName": "Margherita",
"additionalToppings": [
"🍅 tomato",
"🍓 strawberry",
"🍍 pineapple",
"🐟 tuna"
]
}
],
"timestamp": 1669202722766
}
So each order record has an id field, some information about the customer, and an array of pizzas ordered. Each pizza has a pizzaName and an array of additionalToppings.
Ingesting the JSON data
Let’s first do an ordinary ingestion using the ingest wizard. Note how the pizzas field does not appear in the list in Parse data:
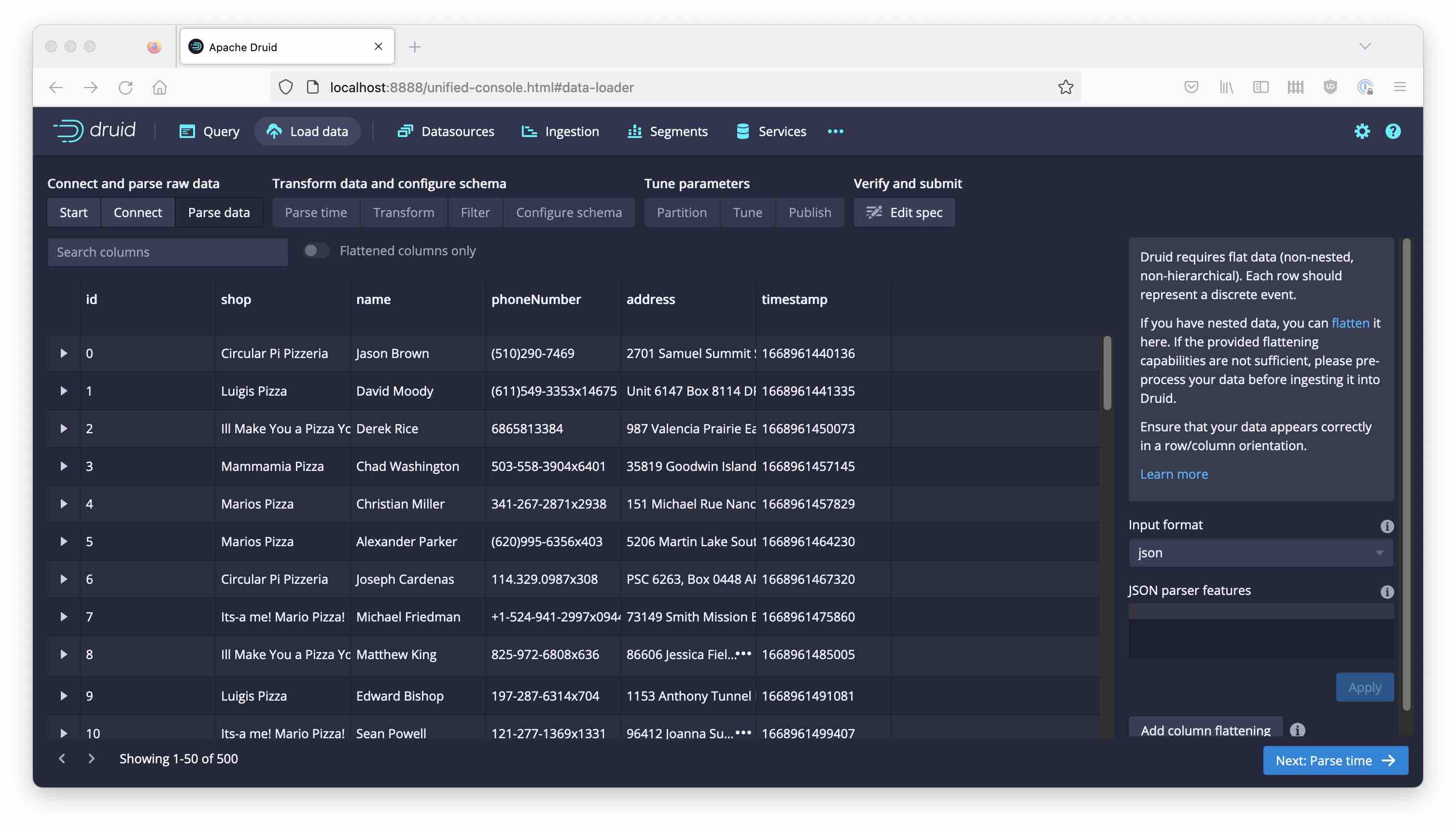
Don’t worry, we will fix that in a moment. Proceed to Configure schema, accepting the defaults.
Add a new dimension:
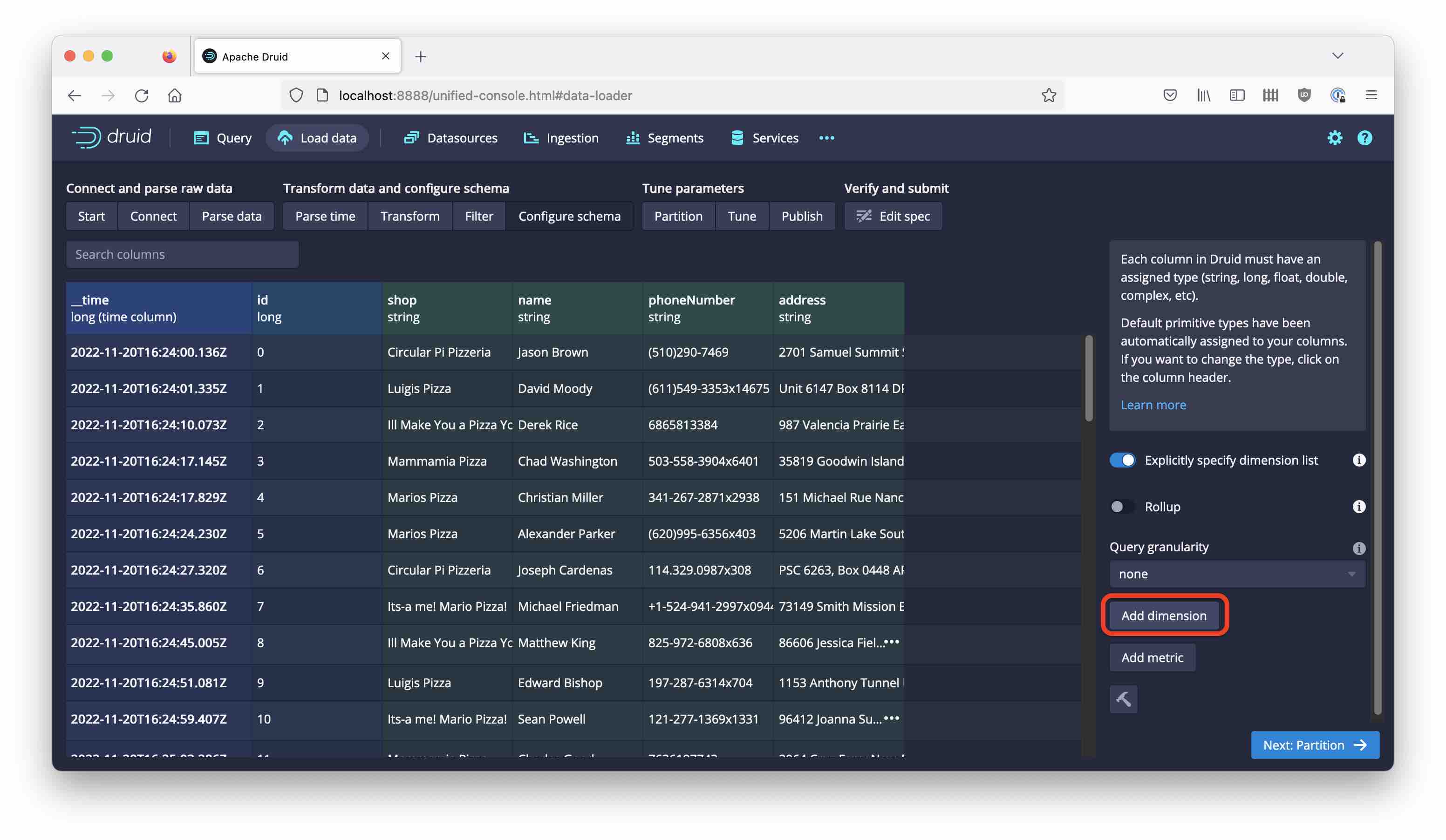
and choose the pizzas field and type json:
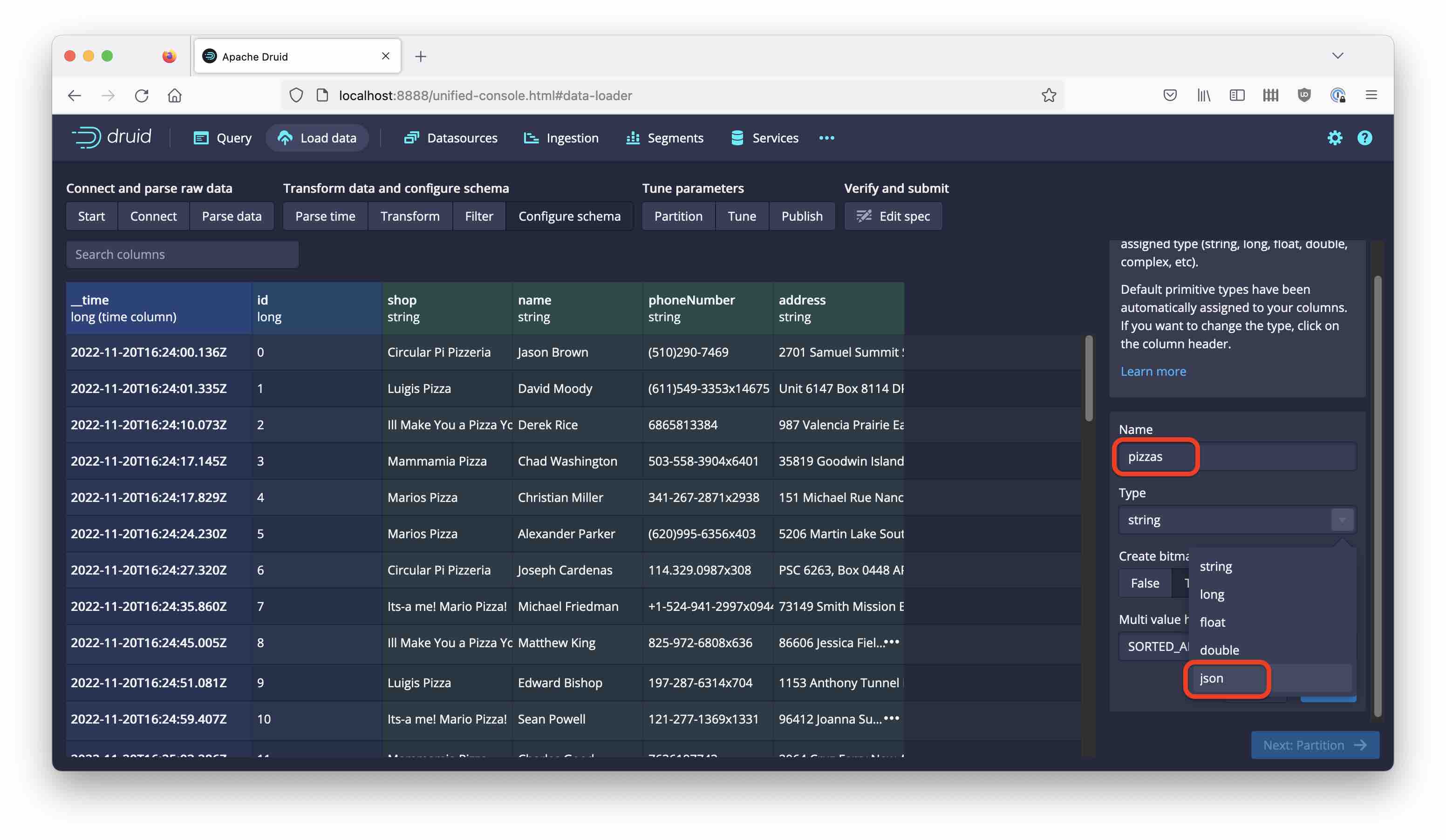
In the following steps, choose daily segments and name the datasource pizza-01.
Here is the ingestion spec:
{
"type": "kafka",
"spec": {
"ioConfig": {
"type": "kafka",
"consumerProperties": {
"bootstrap.servers": "localhost:9092"
},
"topic": "pizza",
"inputFormat": {
"type": "json"
},
"useEarliestOffset": true
},
"tuningConfig": {
"type": "kafka"
},
"dataSchema": {
"dataSource": "pizza-01",
"timestampSpec": {
"column": "timestamp",
"format": "millis"
},
"dimensionsSpec": {
"dimensions": [
{
"type": "long",
"name": "id"
},
"shop",
"name",
"phoneNumber",
"address",
{
"type": "json",
"name": "pizzas"
}
]
},
"granularitySpec": {
"queryGranularity": "none",
"rollup": false,
"segmentGranularity": "day"
}
}
}
}
Let’s query the data:
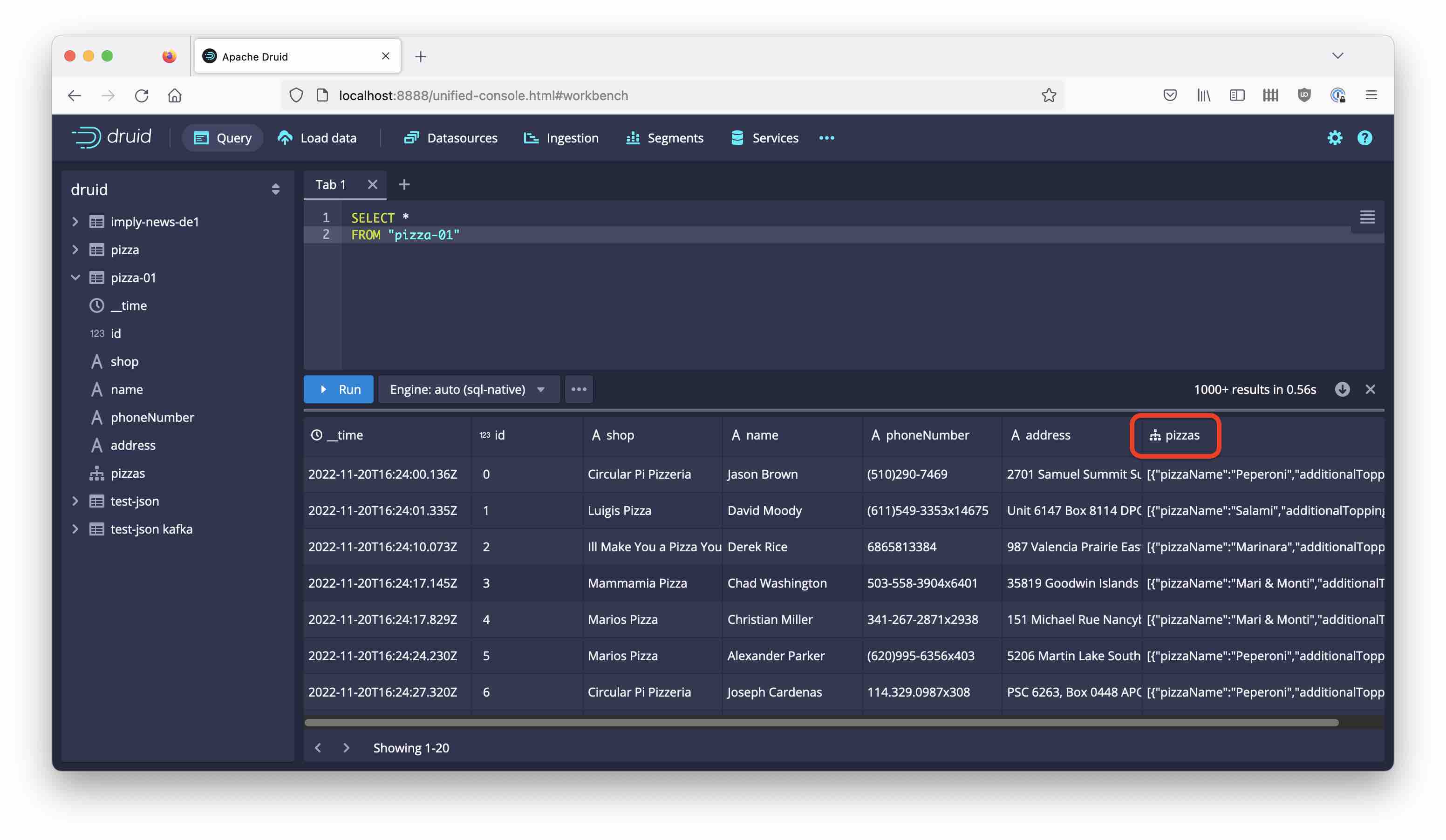
The pizzas column has been ingested correctly. The tree symbol next to the column shows that it is a nested JSON column and you can query it further with JSON functions.
Adding the Kafka timestamp
Instead of the timestamp field inside the data, we would now like to use the Kafka builtin timestamp. This means we have to replace the inputFormat object. A Kafka inputFormat object can read all the data from a Kafka message, including:
- the timestamp
- the key
- Kafka header fields.
It also needs nested input format objects that define how to parse the key and value of the Kafka message. The value format is json, the key is a single string, modeled as a degenerate csv format.
Edit the ingestion spec in the JSON editor. Find the inputFormat section and replace it with this snippet:
"inputFormat": {
"type": "kafka",
"headerLabelPrefix": "kafka.header.",
"timestampColumnName": "kafka.timestamp",
"keyColumnName": "kafka.key",
"headerFormat": {
"type": "string"
},
"keyFormat": {
"type": "csv",
"columns": [
"k"
]
},
"valueFormat": {
"type": "json"
}
}
Also replace the timestampSpec with this:
"timestampSpec": {
"column": "kafka.timestamp",
"format": "millis"
}
Name the datasource for this experiment pizza-02. Submit the spec.
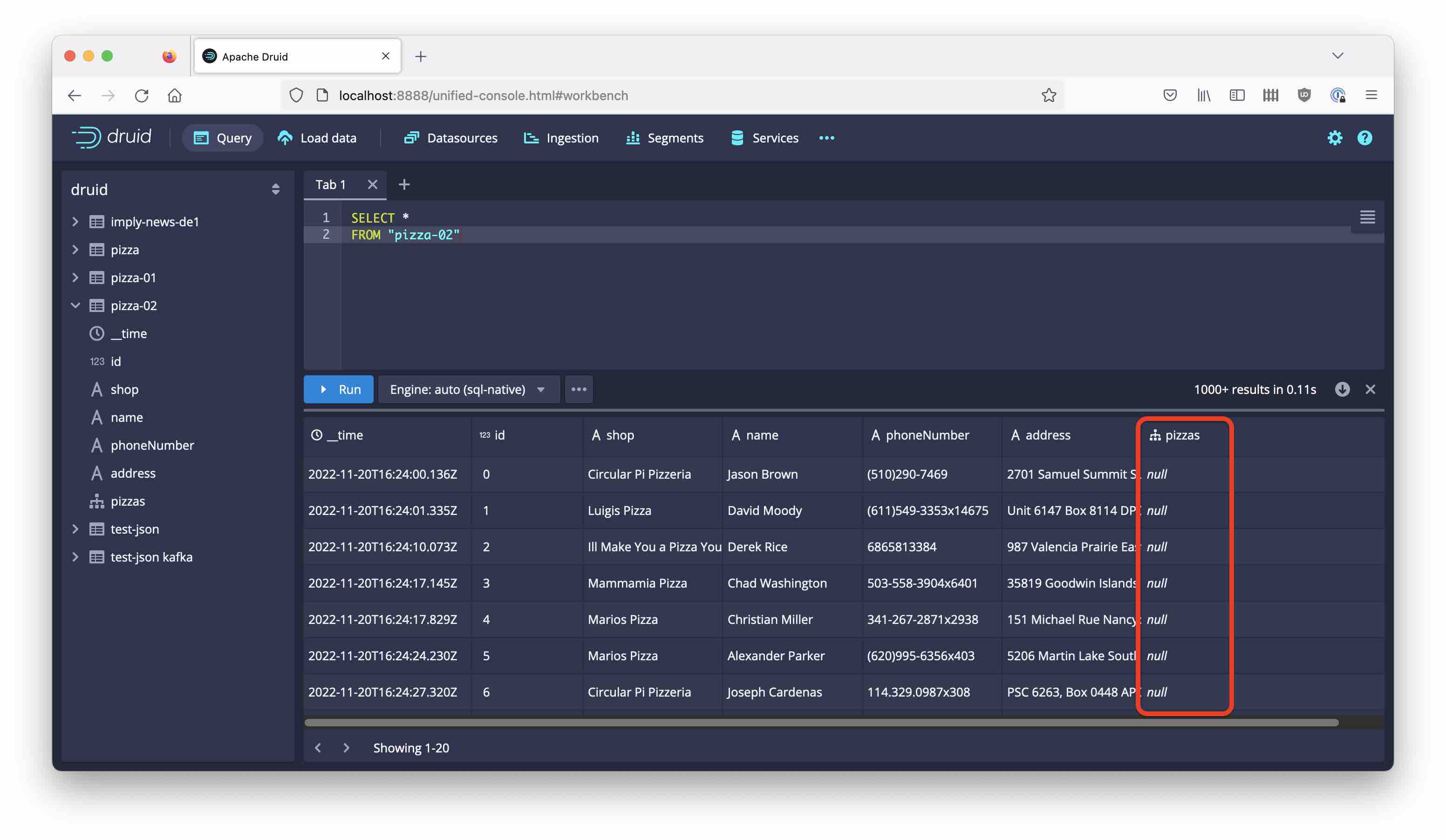
Oh no! The JSON data have not been picked up.
Fixing field discovery using flattenSpec
Here is where an explicit flattenSpec comes to the rescue. It is inserted into the value’s input format and uses the "root" field type to tell Druid to pick up whatever is in the field:
"inputFormat": {
"type": "kafka",
"headerLabelPrefix": "kafka.header.",
"timestampColumnName": "kafka.timestamp",
"keyColumnName": "kafka.key",
"headerFormat": {
"type": "string"
},
"keyFormat": {
"type": "csv",
"columns": [
"k"
]
},
"valueFormat": {
"type": "json",
"flattenSpec": {
"useFieldDiscovery": true,
"fields": [
{ "name": "pizzas", "type": "root" }
]
}
}
Name this datasource pizza-03. This time, the JSON data has been ingested correctly!
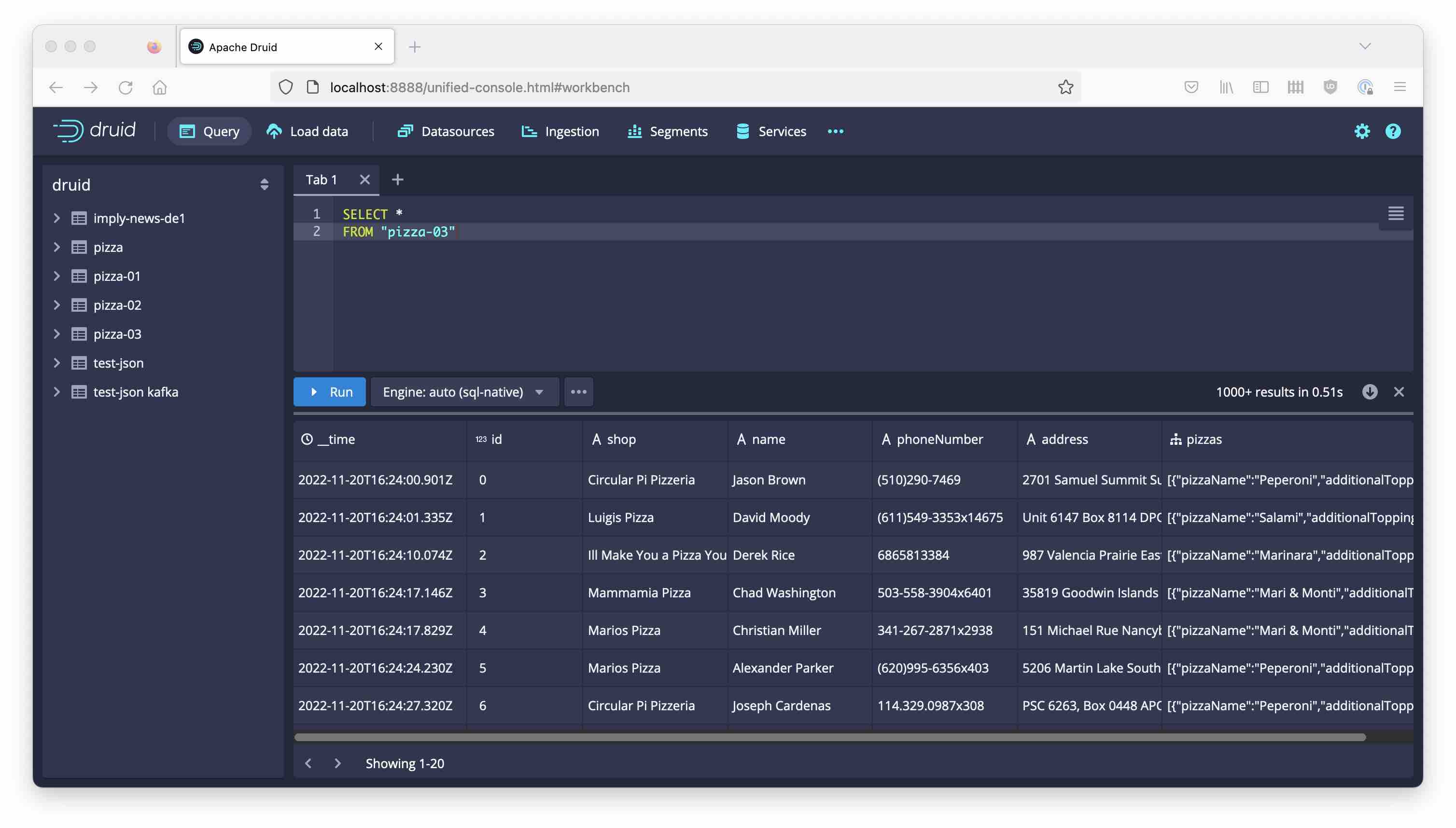
Here is the final ingestion spec:
{
"type": "kafka",
"spec": {
"ioConfig": {
"type": "kafka",
"consumerProperties": {
"bootstrap.servers": "localhost:9092"
},
"topic": "pizza",
"inputFormat": {
"type": "kafka",
"headerLabelPrefix": "kafka.header.",
"timestampColumnName": "kafka.timestamp",
"keyColumnName": "kafka.key",
"headerFormat": {
"type": "string"
},
"keyFormat": {
"type": "csv",
"columns": [
"k"
]
},
"valueFormat": {
"type": "json",
"flattenSpec": {
"useFieldDiscovery": true,
"fields": [
{
"name": "pizzas",
"type": "root"
}
]
}
}
},
"useEarliestOffset": true
},
"tuningConfig": {
"type": "kafka"
},
"dataSchema": {
"dataSource": "pizza-03",
"timestampSpec": {
"column": "kafka.timestamp",
"format": "millis"
},
"dimensionsSpec": {
"dimensions": [
{
"type": "long",
"name": "id"
},
"shop",
"name",
"phoneNumber",
"address",
{
"type": "json",
"name": "pizzas"
}
]
},
"granularitySpec": {
"queryGranularity": "none",
"rollup": false,
"segmentGranularity": "day"
}
}
}
}
Conclusion
- Nested columns allow structured JSON data inside Druid datasources.
- This can replace
flattenSpecin some use cases. - However, with a
kafkainputFormat, you need to define each nested column field explicitly in theflattenSpec.
"Pizza" by Katrin Gilger is licensed under CC BY-SA 2.0 ![]()
![]()
![]() .
.