Timeseries Data in Apache Druid: Getting the Latest Value with Rolled Up Data

Imagine you are analyzing time based data and your most frequent queries are about retrieving the latest values for each time interval. One example would be stock ticker data where you would most likely want to know the closing prices for each trading day. IoT related use cases are another scenario where this would be useful.
This is easy to achieve using detail data. After all, Druid comes with LATEST and EARLIEST aggregators that give you exactly what you asked for. But you cannot use rollup because that would limit the granularity, and it would lead to incorrect results with imperfect rollup such as in realtime ingestion. That is why you cannot use those aggregators during rollup.
Or can you?
In this tutorial, I show how to use latest/earliest value aggregation with rollup in Druid. The tutorial works with the Druid 0.23 quickstart.
Using LATEST with Rollup
It turns out that you can use a LATEST (or EARLIEST) aggregator during rollup. This behavior is currently implemented only for the STRING flavor of the aggregator: if you want to aggregate over a numeric field, you will have to use a cast. Hopefully this will change in a future release of Druid.
Here is a minimalistic data sample with stock prices.
timestamp,symbol,price
2022-08-10 10:01:00,AAAA,25.90
2022-08-10 10:11:00,AAAA,26.90
2022-08-10 11:55:00,AAAA,28.10
Ingest those data with hourly rollup. The LATEST aggregator is not available in the ingestion wizard, so you will have to edit the ingestion spec manually. It should look like this:
{
"type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "inline",
"data": "timestamp,symbol,price\n2022-08-10 10:01:00,AAAA,25.90\n2022-08-10 10:11:00,AAAA,26.90\n2022-08-10 11:55:00,AAAA,28.10"
},
"inputFormat": {
"type": "csv",
"findColumnsFromHeader": true
}
},
"tuningConfig": {
"type": "index_parallel",
"partitionsSpec": {
"type": "hashed"
},
"forceGuaranteedRollup": true
},
"dataSchema": {
"dataSource": "ticker_data",
"timestampSpec": {
"column": "timestamp",
"format": "auto"
},
"dimensionsSpec": {
"dimensions": [
"symbol"
]
},
"granularitySpec": {
"queryGranularity": "hour",
"rollup": true,
"segmentGranularity": "hour"
},
"metricsSpec": [
{
"name": "count",
"type": "count"
},
{
"name": "last_price",
"type": "stringLast",
"fieldName": "price"
}
]
}
}
}
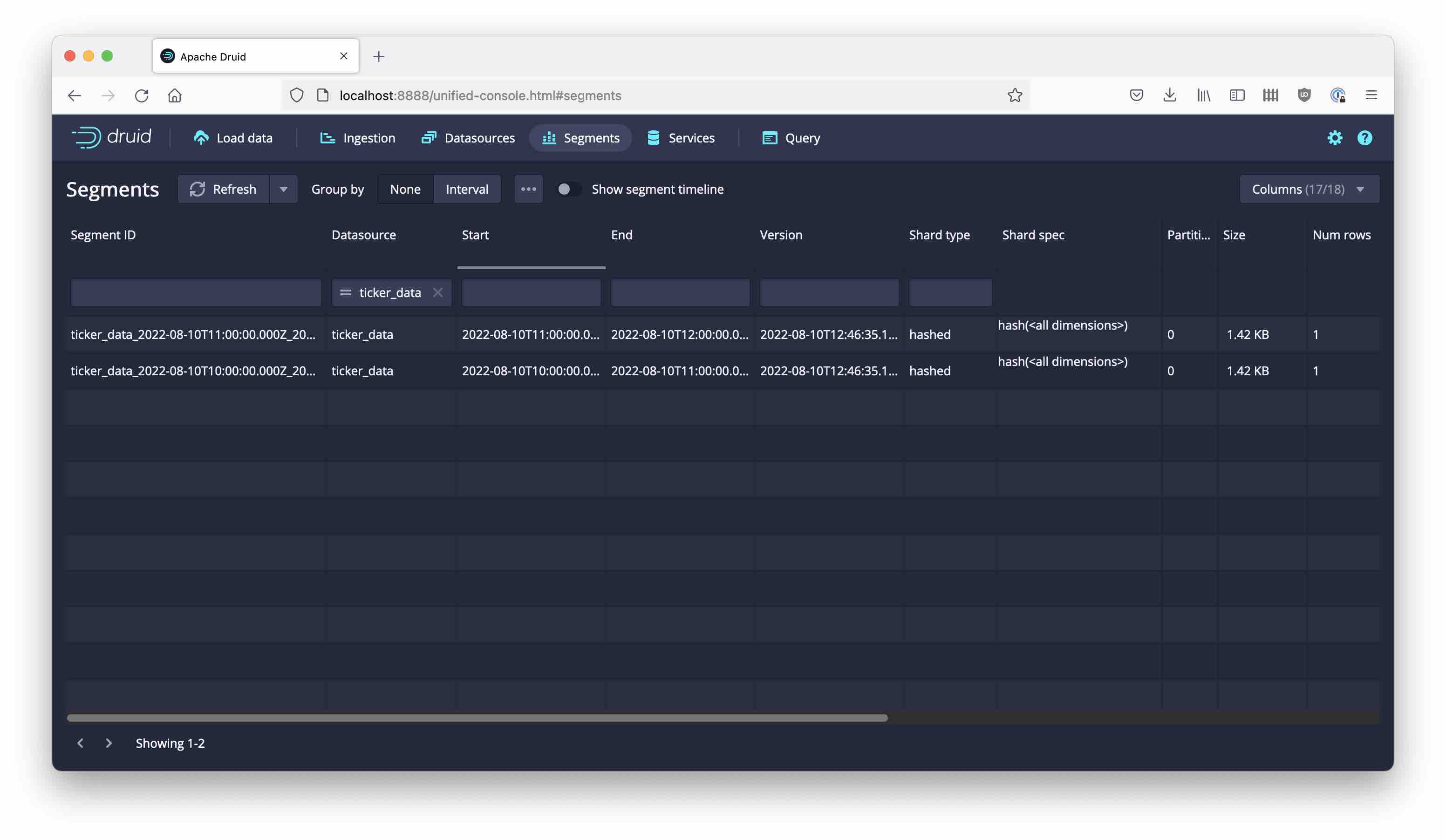
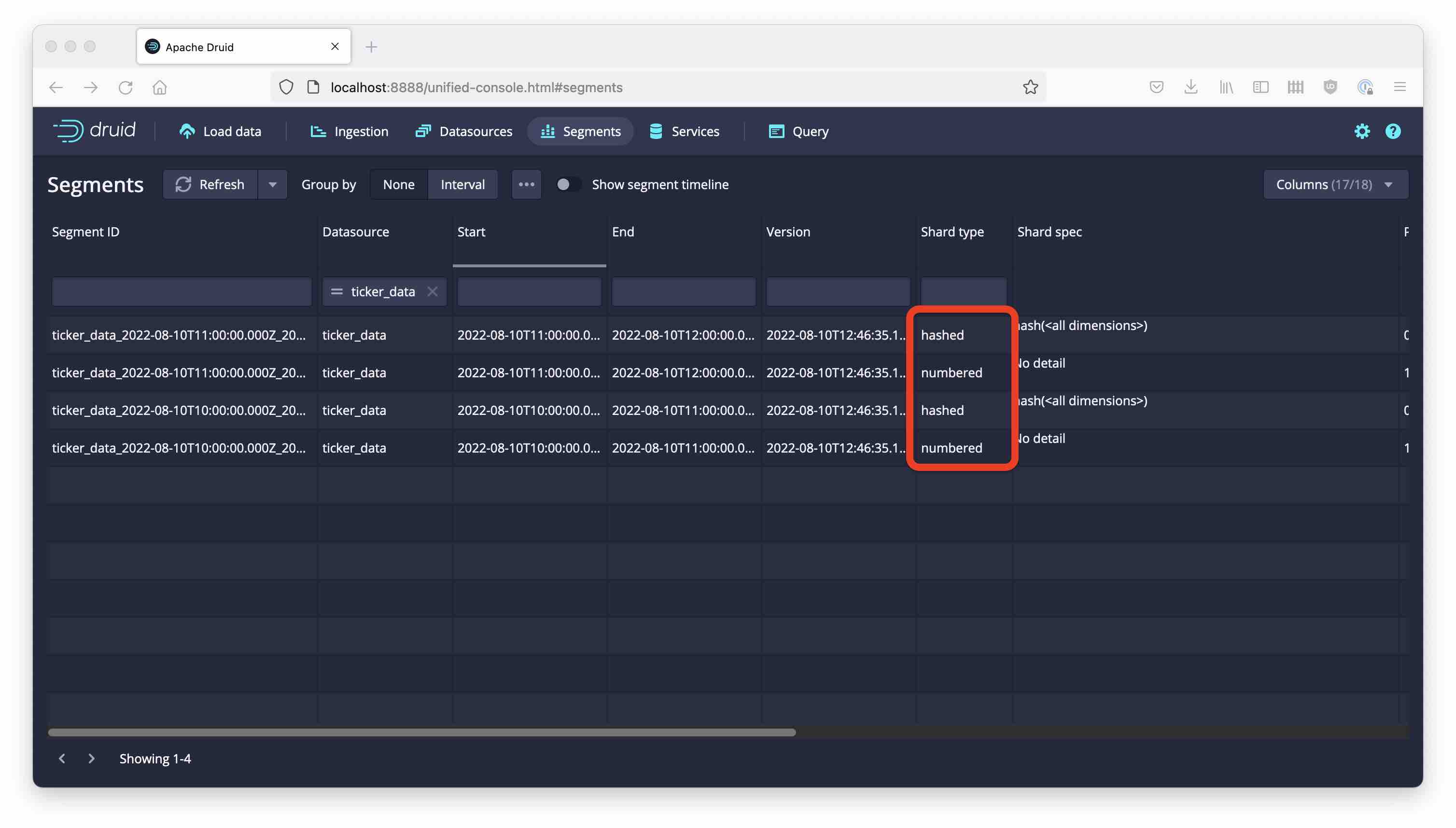
What have we got now? A glance at the Segments view shows that there are two (hourly) segments with one row each:
Let’s query the data:
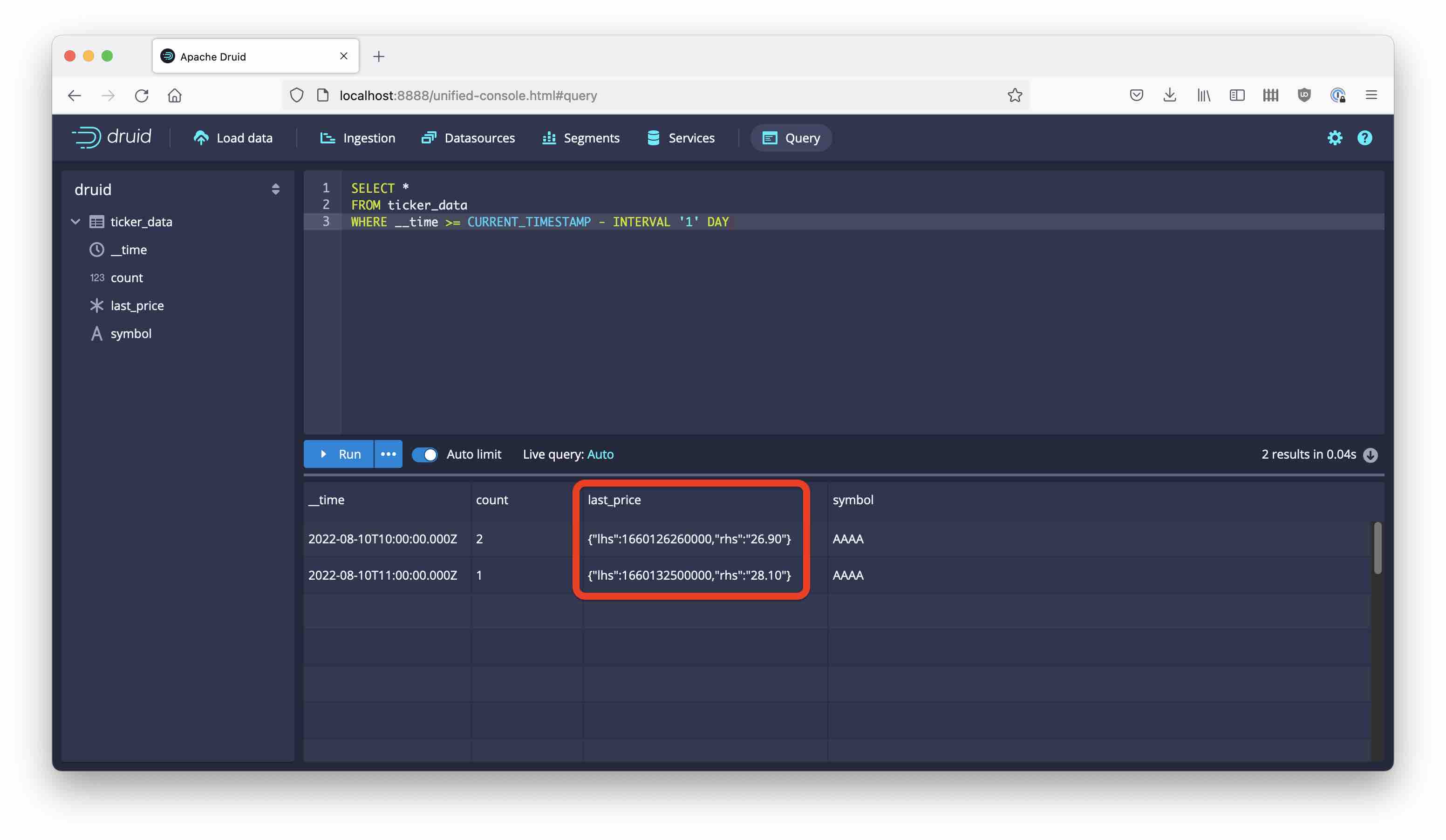
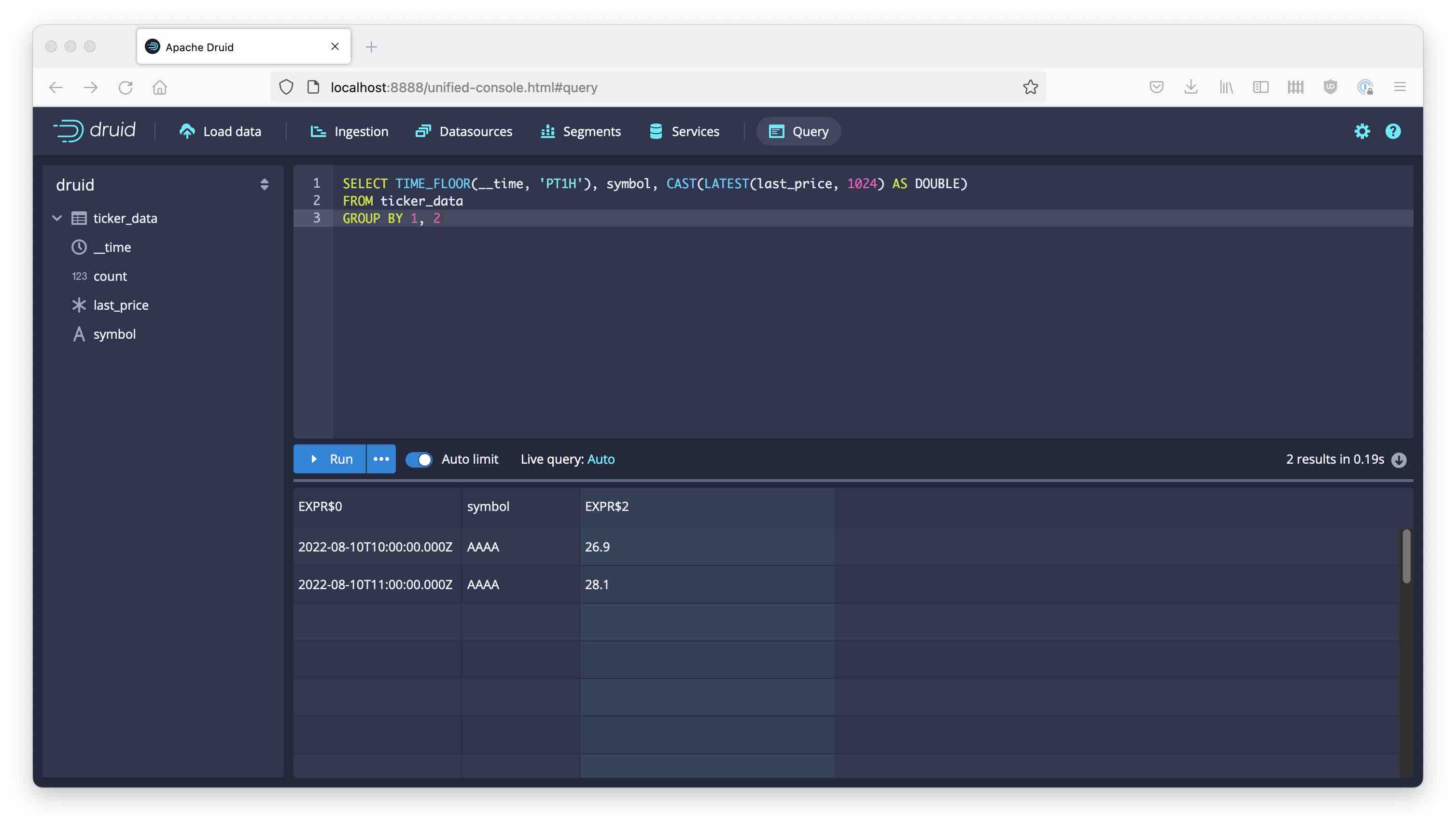
The last_price column is not a single value but a tuple of timestamp and value. Druid stored an intermediate result for us. (Technically, this is a COMPLEX data type.) Getting the numeric value needs another aggregation step by means of a GROUP BY query:
SELECT TIME_FLOOR(__time, 'PT1H'), symbol, CAST(LATEST(last_price, 1024) AS DOUBLE)
FROM ticker_data
GROUP BY 1, 2
Adding More Data
What happens if more data is added? These will end up in extra segments until a compaction is executed. Let’s add a small data set.
timestamp,symbol,price
2022-08-10 10:50:00,AAAA,23.90
2022-08-10 11:20:00,AAAA,22.10
Note how the first new row is later than existing rows for that hour. The second new row isn’t.
To add these data, we have to make a few changes to the ingestion spec:
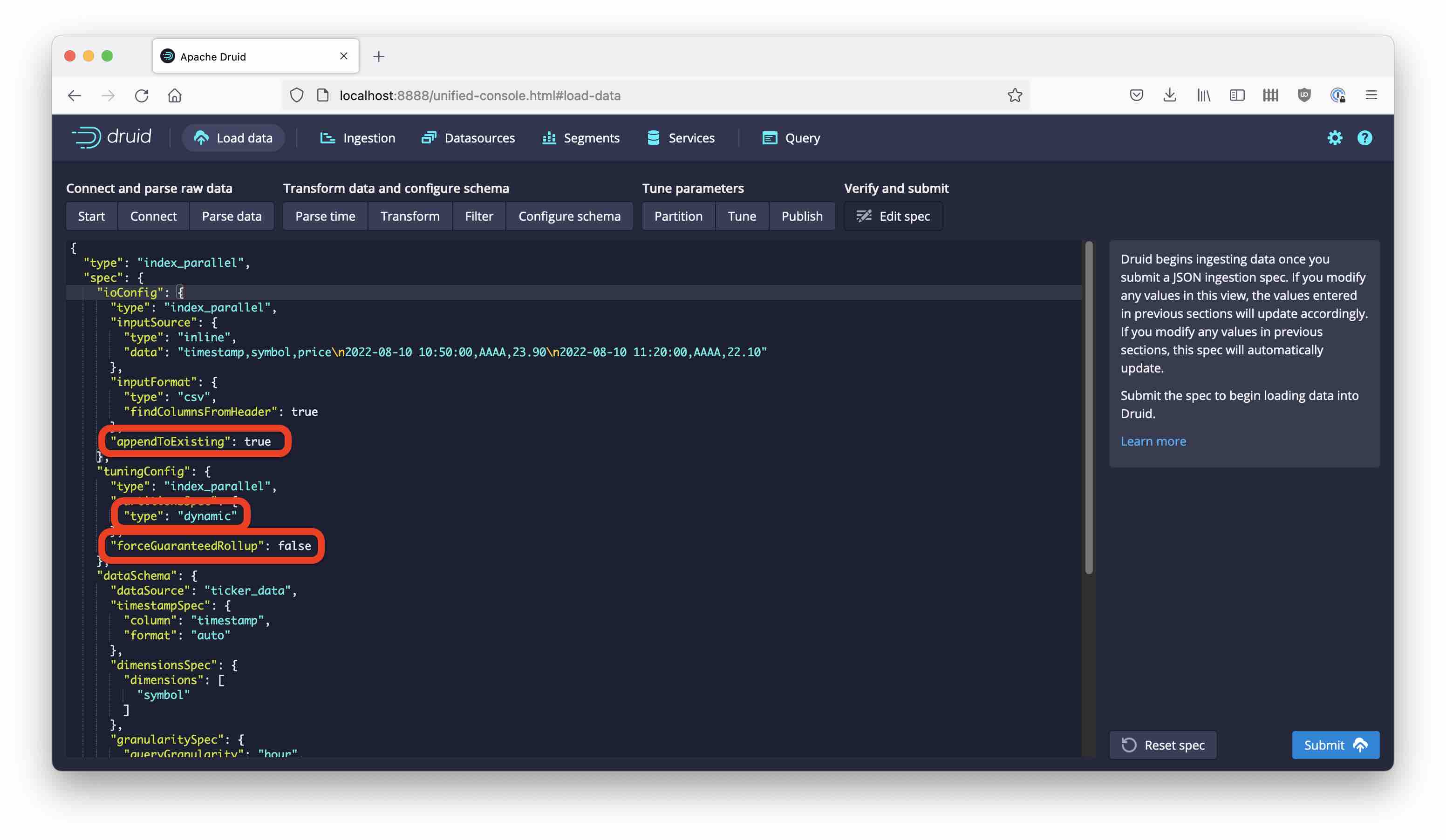
- Set
appendToExistingtotrueinioConfig - The partition strategy has to be set to
dynamic - Unset
forceGuaranteedRollup
Here is the complete ingestion spec:
{
"type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "inline",
"data": "timestamp,symbol,price\n2022-08-10 10:50:00,AAAA,23.90\n2022-08-10 11:20:00,AAAA,22.10"
},
"inputFormat": {
"type": "csv",
"findColumnsFromHeader": true
},
"appendToExisting": true
},
"tuningConfig": {
"type": "index_parallel",
"partitionsSpec": {
"type": "dynamic"
},
"forceGuaranteedRollup": false
},
"dataSchema": {
"dataSource": "ticker_data",
"timestampSpec": {
"column": "timestamp",
"format": "auto"
},
"dimensionsSpec": {
"dimensions": [
"symbol"
]
},
"granularitySpec": {
"queryGranularity": "hour",
"rollup": true,
"segmentGranularity": "hour"
},
"metricsSpec": [
{
"name": "count",
"type": "count"
},
{
"name": "last_price",
"type": "stringLast",
"fieldName": "price"
}
]
}
}
}
We now have four segments. The two previous segments have shard type hashed, which is the default; the new segments have type numbered which corresponds to dynamic partitioning.
Rerun the same aggregation query as before.
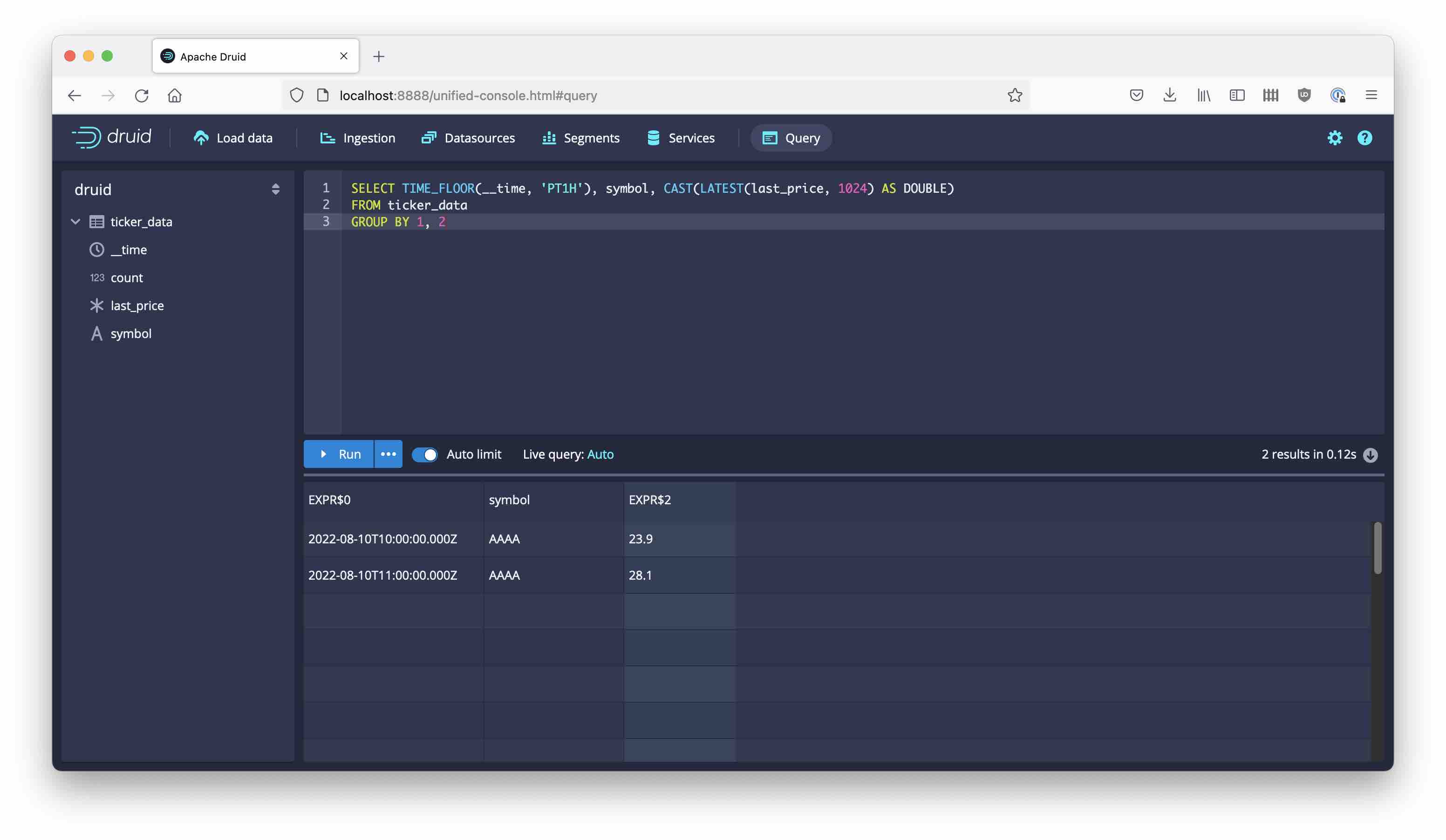
The result is as expected. Druid has correctly picked up the latest value for each hourly interval.
Learnings
- Druid can use
LATESTorEARLIESTaggregations during ingestion. - Druid stores these aggregations in an intermediate representation that allows for adding more data later.
- In the current version, this requires working with
STRINGfields. - For numeric fields, you can work around this limitation using a
CASTexpression.
"Graph With Stacks Of Coins" by kenteegardin is licensed under CC BY-SA 2.0 ![]()
![]()
![]() .
.