New in Druid 0.23: Ingesting Kafka Keys and Timestamps
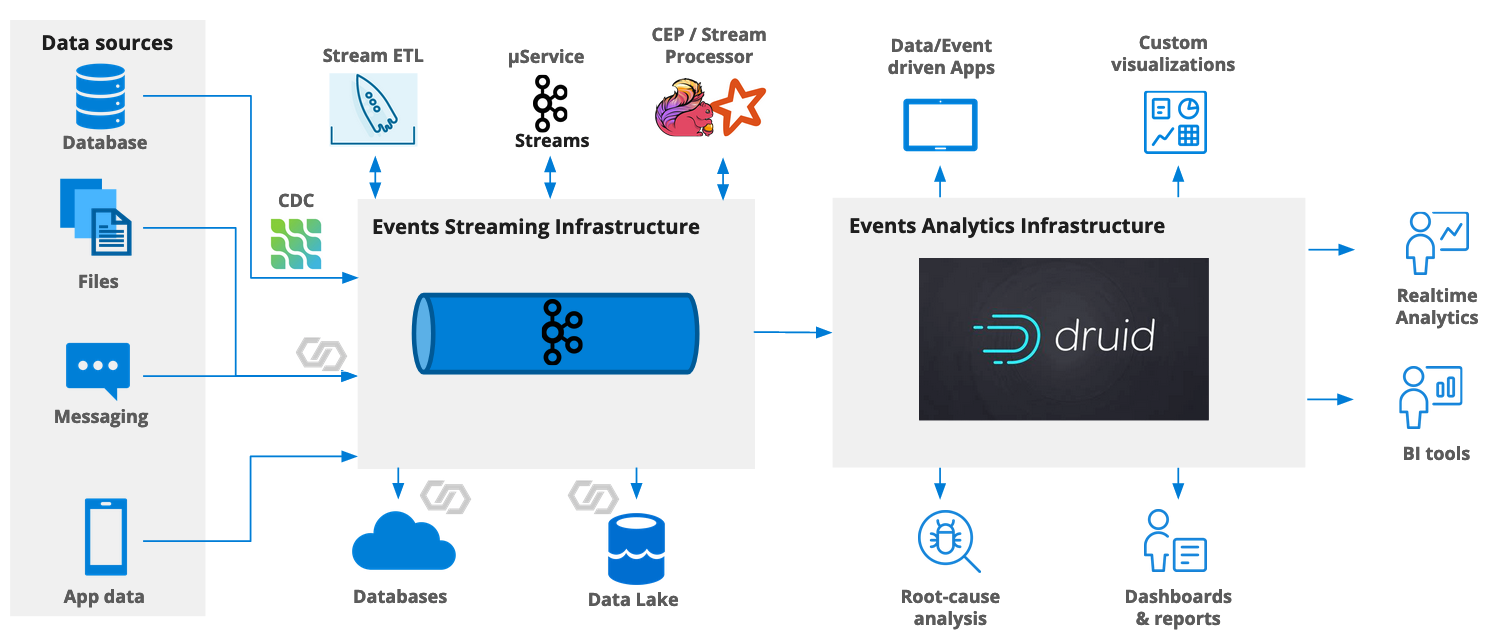
Among the many new features in Druid 0.23 is the ability to handle Kafka metadata upon ingestion. This includes
- the Kafka timestamp
- the message key
- Kafka message headers.
While customers of Imply have been able to take advantage of this functionality for a few months already, it is still officially considered an alpha feature. But why would we want this anyway?
Let’s have a look!
Why Does It Matter?
Up until now, Druid’s Kafka ingestion module used to look only at the Kafka message value. But if you try to optimize your Kafka partitioning strategy, you would usually set up a partitioning key that gives you the ability to both scale and parallelize, and to have a partial order guarantee in your message stream. This is important when you look at message streams that have the notion of a session or a transaction which is tied together by a common session ID field and where the order of events matters.
In that case it makes a lot of sense to make the session ID the Kafka key, and having it again inside the message value would be an unnecessary data duplication.
Modern stream processing systems like Confluent’s ksqlDB honor this fact: if you create a new stream joining two source streams (or a stream and a table, for that matter), the join key will be made the new Kafka message key, and it will not be represented in the message value unless you put a copy there explicitly. Thus, having the ability to ingest the key directly simplifies the preprocessing pipeline and makes it more organic.
Likewise, a Kafka message always has a timestamp. In the absence of other information, this would be the time when the message has been produced into Kafka. But for many cases this is good enough, and again, with pre-0.23 Druid, you would have to create another timestamp field inside the message for it to be ingested.
Lastly, Kafka headers are used by some systems to track data provenance and lineage. In order to fit into the larger context of a data governance architecture, you would want to preserve and/or process Kafka headers as the data makes its way into and through Druid.
I am going to present a short tutorial that shows how to handle Kafka keys and timestamps within Druid. Headers work very similary and are left as an exercise for the reader.
Setting Up Kafka
You will need a Kafka service for this tutorial. If you don’t have one ready, you can install it on your laptop using Confluent’s Community Docker images, as I have covered in detail in a previous post.
For this tutorial, you will need just a Kafka broker and Zookeeper. Here’s the Docker compose file:
---
version: '2'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.0.1
hostname: zookeeper
container_name: zookeeper
ports:
- "12181:12181"
environment:
ZOOKEEPER_CLIENT_PORT: 12181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.0.1
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "29092:29092"
- "9092:9092"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:12181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
Leave the default configuration in place - among other options, this will auto-create a topic as soon as we produce into it.
You will also need kcat as a Kafka client. Although this is an open source tool, you can find valuable information about it on Confluent’s pages.
I prefer kcat over the built-in client utilities because it is more flexible. For instance, it comes with format options to include keys and to show metadata along with the message itself in consumer mode.
Let’s produce some data with keys and with implicit timestamps. Between messages, we wait a random number of seconds in order to get different timestamps:
#!/bin/bash
BROKER=localhost:9092
TOPIC=keytest
for i in {1..20}; do
echo 'key'$i'|{ "val": '$i' }' | kcat -b $BROKER -P -t $TOPIC -K "|"
sleep $(( $RANDOM % 10 + 1 ))
done
Note how the message payload is JSON but the key is a single string. We’ll have to handle that in our ingestion spec.
Check if it worked:
% kcat -b localhost:9092 -C -t keytest -f "%T|%k|%s\n" -o 0
1656244527236|key1|{ "val": 1 }
1656244537317|key2|{ "val": 2 }
1656244539390|key3|{ "val": 3 }
1656244544463|key4|{ "val": 4 }
1656244550541|key5|{ "val": 5 }
1656244552618|key6|{ "val": 6 }
1656244559692|key7|{ "val": 7 }
1656244562774|key8|{ "val": 8 }
1656244570850|key9|{ "val": 9 }
1656244578930|key10|{ "val": 10 }
1656244589003|key11|{ "val": 11 }
1656244596080|key12|{ "val": 12 }
1656244605156|key13|{ "val": 13 }
1656244614233|key14|{ "val": 14 }
1656244617309|key15|{ "val": 15 }
1656244625386|key16|{ "val": 16 }
1656244631460|key17|{ "val": 17 }
1656244639540|key18|{ "val": 18 }
1656244643610|key19|{ "val": 19 }
1656244651682|key20|{ "val": 20 }
% Reached end of topic keytest [0] at offset 20
This shows the timestamp (in milliseconds since Epoch), the message key and value. We are good to go!
Ingesting the Data
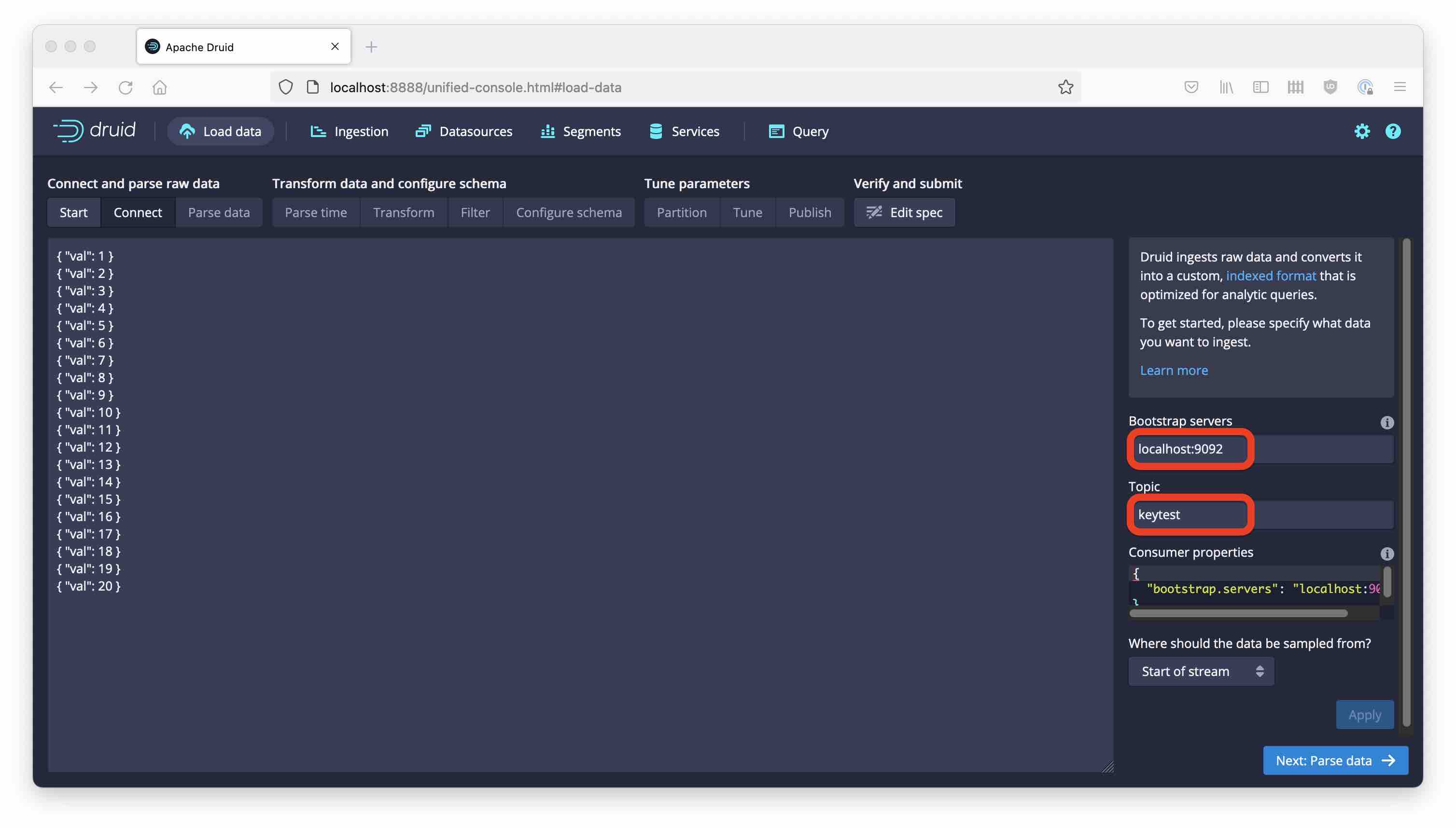
Set up Druid 0.23 according to the quickstart instructions and point your browser to http://localhost:8888. Open up the Load data wizard and connect to your Kafka topic:
Proceed to Parse data and make sure that the JSON payload is parsed correctly. Note how we don’t yet see the key or timestamp.
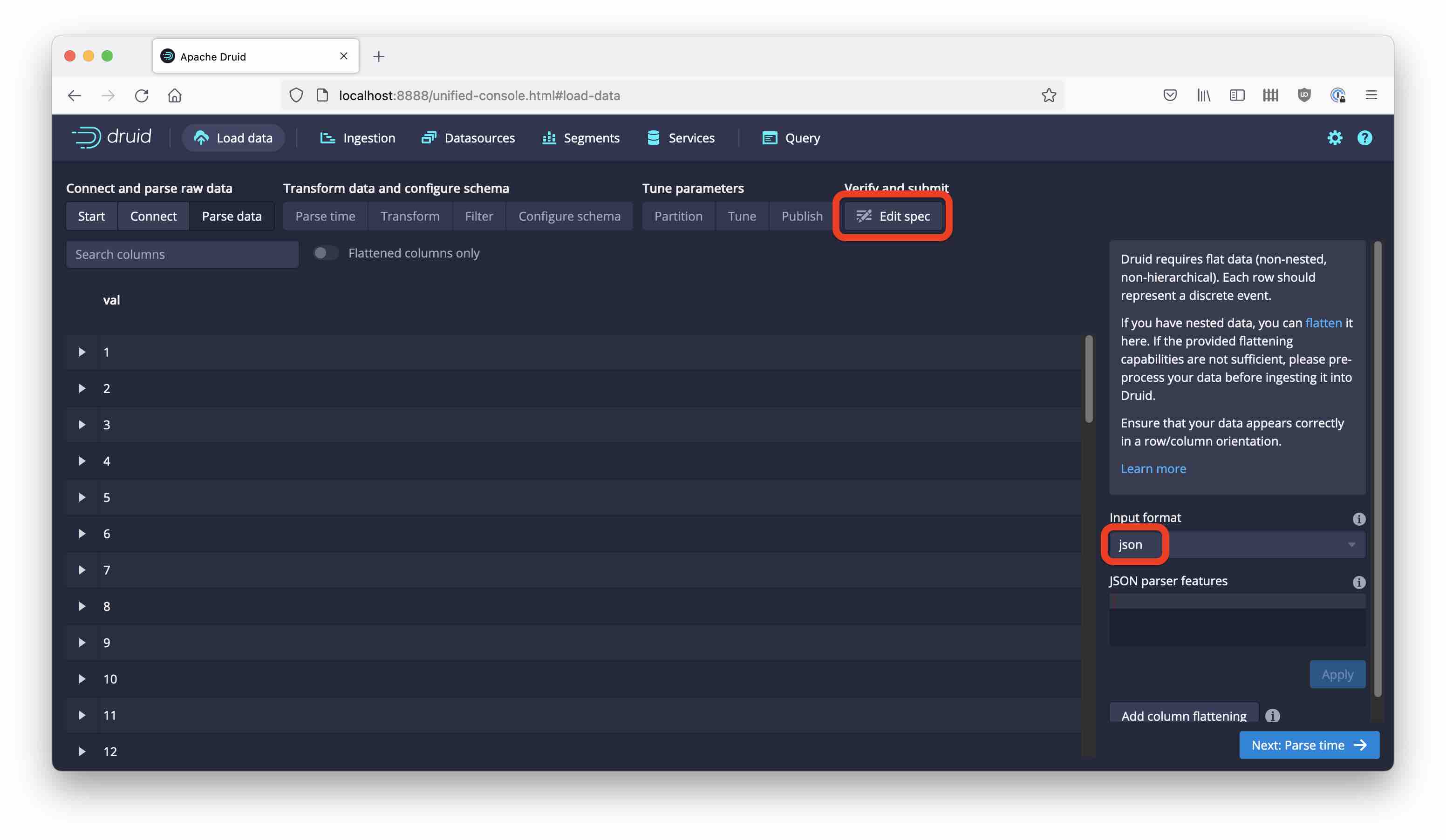
From here, go directly to Edit spec. The additional Kafka functionality is not yet supported by the GUI, so we are going to need to edit the ingestion spec manually. The details are documented in the Kafka Supervisor and Data formats sections of the Druid docs.
Here is what I got so far:
{
"type": "kafka",
"spec": {
"ioConfig": {
"type": "kafka",
"consumerProperties": {
"bootstrap.servers": "localhost:9092"
},
"topic": "keytest",
"inputFormat": {
"type": "json"
}
},
"tuningConfig": {
"type": "kafka"
},
"dataSchema": {
"dataSource": "keytest"
}
}
}
Edit the ingestion spec. The inputFormat type will be "kafka" instead of "json". Also, there have to be nested inputFormats for the key and value. For the value, this will be json. The key is a single string, which is conveniently viewed as a degenerate CSV format with only one column and no headers.
I am also setting useEarliestOffset to read from the beginning of the topic, and I am adding the dimensions manually.
Here’s the final result:
{
"type": "kafka",
"spec": {
"ioConfig": {
"type": "kafka",
"consumerProperties": {
"bootstrap.servers": "localhost:9092"
},
"topic": "keytest",
"useEarliestOffset": true,
"inputFormat": {
"type": "kafka",
"headerLabelPrefix": "kafka.header.",
"timestampColumnName": "kafka.timestamp",
"keyColumnName": "kafka.key",
"headerFormat": {
"type": "string"
},
"keyFormat": {
"type": "csv",
"columns": [
"k"
]
},
"valueFormat": {
"type": "json"
}
}
},
"tuningConfig": {
"type": "kafka"
},
"dataSchema": {
"dataSource": "keytest",
"timestampSpec": {
"column": "kafka.timestamp",
"format": "millis"
},
"dimensionsSpec": {
"dimensions": [
"kafka.key",
{
"name": "val",
"type": "LONG"
}
]
}
}
}
}
Paste this into the spec editor and submit.
After a short while, you can see the data:
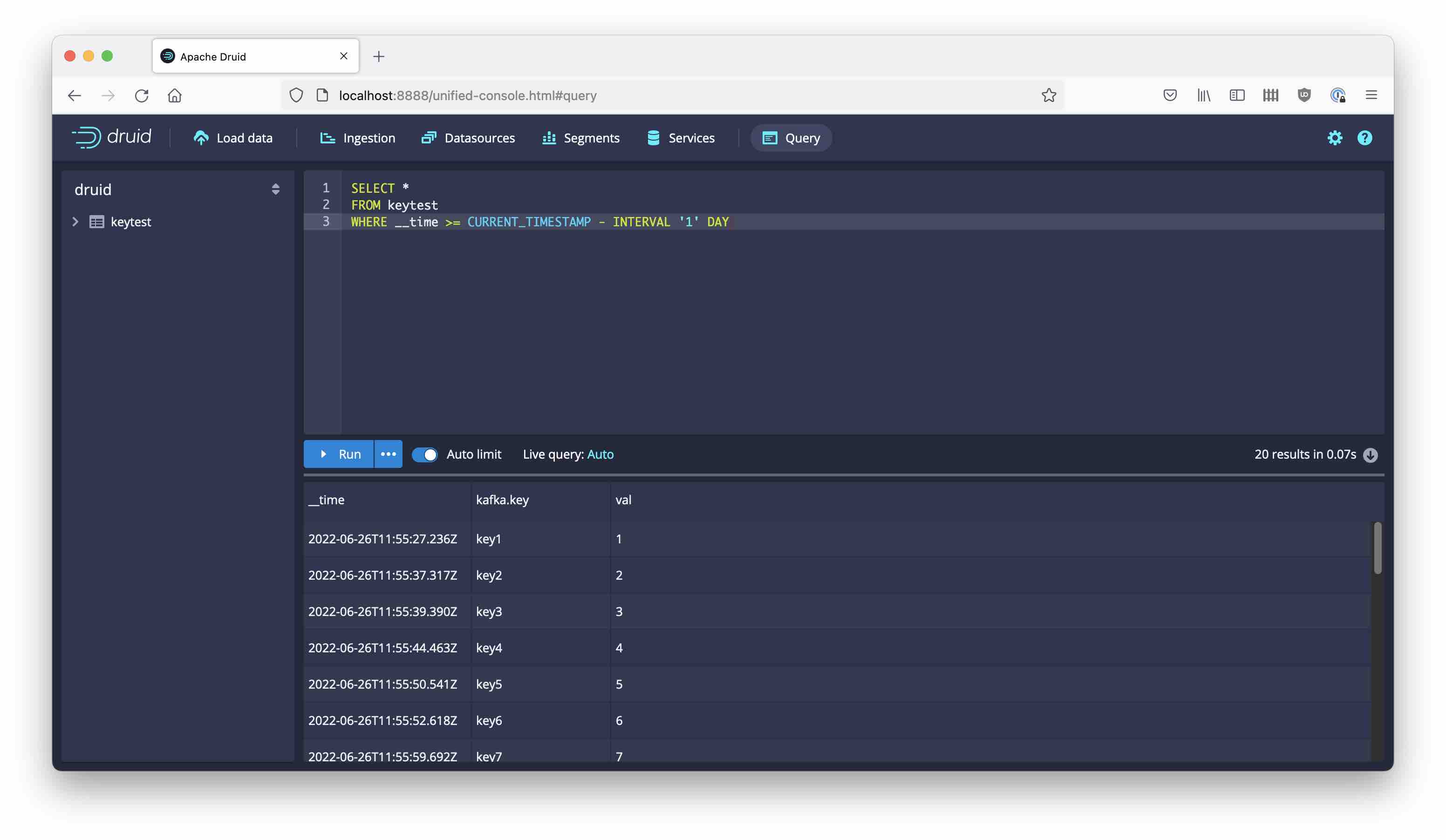
Learnings
- Druid can now ingest not only the Kafka payload but also key, headers, and timestamp.
- While the engine supports the Kafka input format, the GUI doesn’t know about it yet. But you can use the JSON editor to create a Kafka spec.
- This fits extremely well with modern stream processing architectures that rely on Kafka keys for their operation, and on headers for data governance.