Druid Data Cookbook: Ingestion Transforms

While Apache Druid is not an ETL tool, it has the ability to transform incoming data to do elementary cleansing or to derive dimension values from sets of input fields. Druid Transforms work on single rows of data. They operate on input fields and they create additional fields in the data. A Transform can overshadow existing field (dimension) names but you cannot use metrics nor other transforms as inputs.
The Druid documentation explains Transforms here. There’s also a tutorial, which is a good place to start if you haven’t used transforms before.
… but we can actually do more! Let’s look at a few recipes how to manipulate data using Transforms.
How to code Transforms
The simplest way to employ Transforms is via the ingestion wizard in the Druid console. Right after the Parse time step, you are greeted with the option to roll your own Transform:
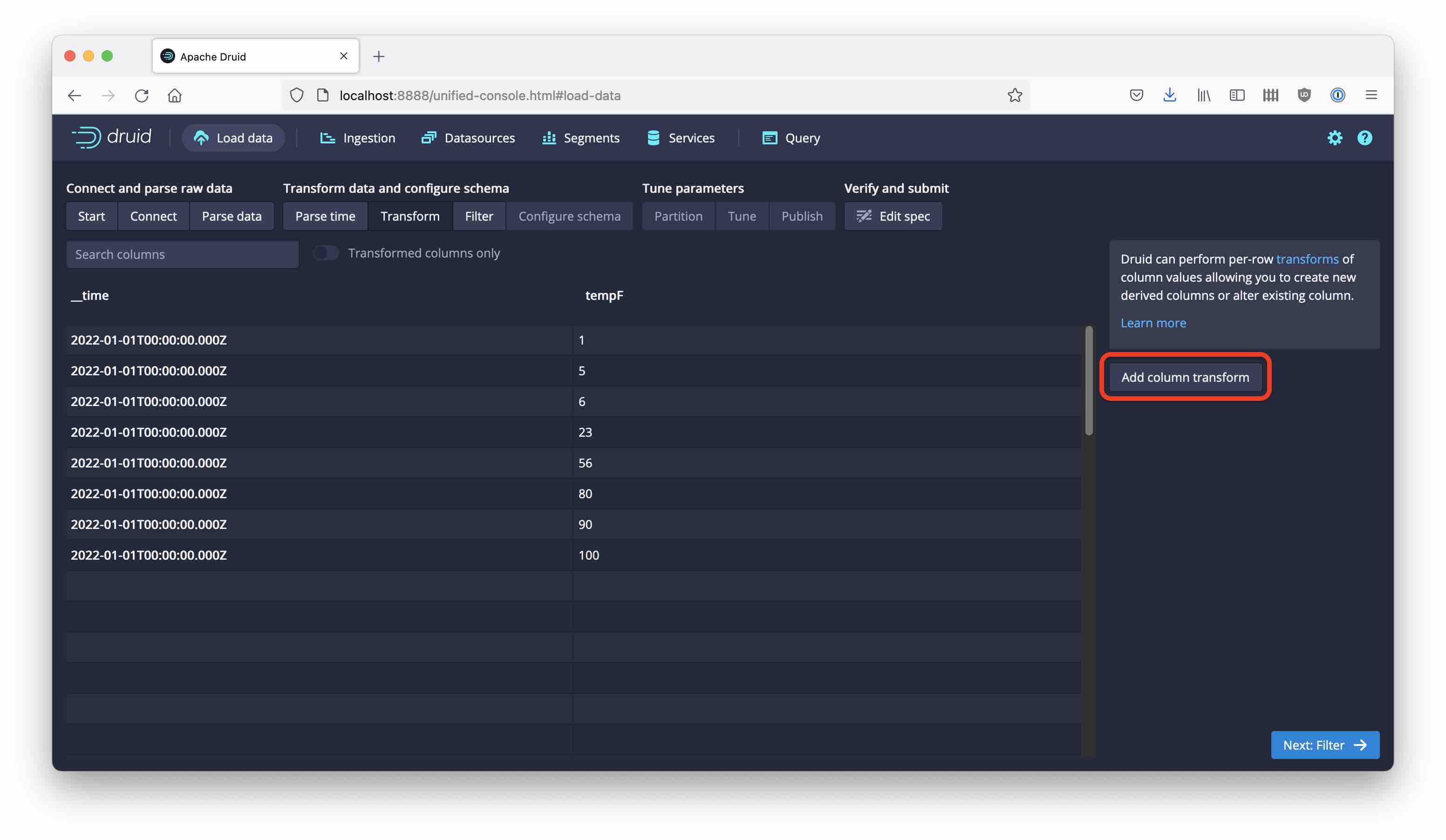
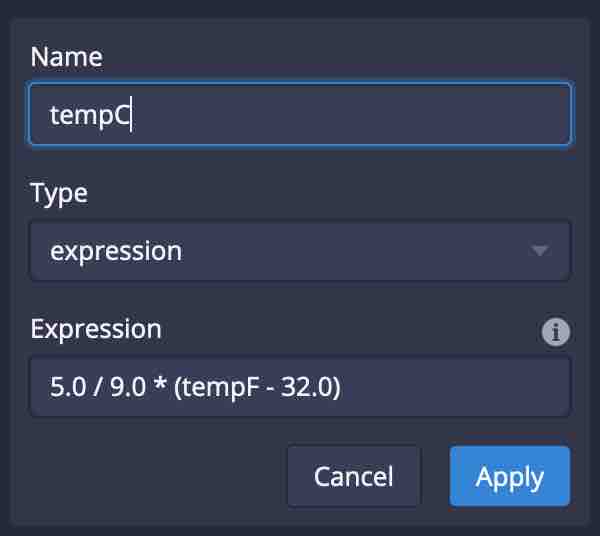
As you hit Add column transform, you can define your transform using the Druid expression syntax:
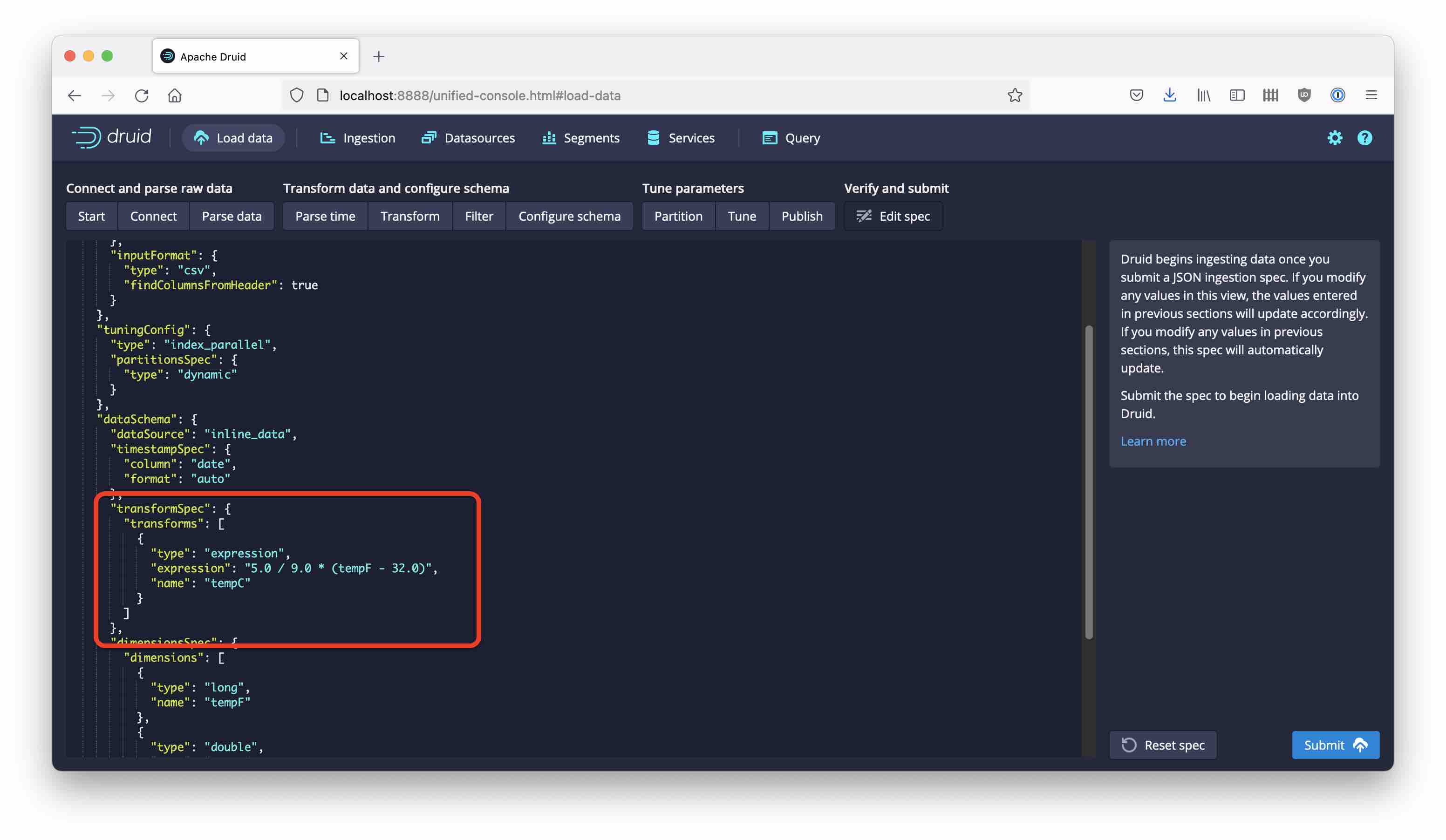
In the ingestion spec, Transforms are defined within the transforms section of the dataSchema. Here is how this might look like:
Quotes in expression syntax work much like in SQL. This means
- string literals are enclosed in single quotes:
'string literal' - identifiers such as field names, if required, are enclosed in double quotes:
"field name".
Since double quotes are also used as string delimiters in JSON, double quotes inside an expression have to be escaped like so: \"field name\". This does not apply when you use the wizard - it will add the escape characters for you.
Armed with this knowledge, feel free to try out some of the examples below.
Simple math transformation
Imagine we have weather data from America that specifies the temperature in Fahrenheit degrees, tempF. As a European, I’d prefer to read the temperature in Celsius degrees.
Here is the formula
{
"type": "expression",
"name": "tempC",
"expression": "5.0 / 9.0 * (tempF - 32.0)"
}
Make sure to use the right kind of numeric types in your formulae! Note how I have been careful to write all the number literals with a decimal point? Druid does make a difference between integer and floating point numbers, and it will perform arithmetic according to the types involved. If you write 5 / 9 * (tempF - 32), you will get all zeroes because an integer division of 5 by 9 yields (integer) 0!
Compose a new dimension out of several fields
If the information to build a dimension is spread across multiple fields, a transform can concatenate them:
{
"type": "expression",
"name": "fullName",
"expression": "concat(\"firstName\", ' ', \"lastName\")"
}
Composite timestamps
Druid is very good at parsing timestamps of various formats. But what if you have to pull the timestamp out of more than one field in your data?
The documentation says:
Transforms can refer to the timestamp of an input row by referring to
__timeas part of the expression. They can also replace the timestamp if you set their “name” to__time.
What does this mean? It means that the __time column value can be overridden by anything you specify in an expression.
Consider this data sample from an ADS-B data collector:
MT,TT,SID,AID,Hex,FID,DMG,TMG,DML,TML,CS,Alt,GS,Trk,Lat,Lng,VR,Sq,Alrt,Emer,SPI,Gnd
MSG,5,111,11111,3C70A8,111111,2016/02/05,04:51:22.894,2016/02/05,04:51:22.888,,36000,,,,,,,0,,0,0
MSG,3,111,11111,484411,111111,2016/02/05,04:51:22.903,2016/02/05,04:51:22.889,,12525,,,52.58052,5.29031,,,,,,0
MSG,5,111,11111,44D1CF,111111,2016/02/05,04:51:22.916,2016/02/05,04:51:22.891,,27025,,,,,,,0,,0,0
MSG,5,111,11111,3C70A8,111111,2016/02/05,04:51:22.917,2016/02/05,04:51:22.891,,36000,,,,,,,0,,0,0
MSG,5,111,11111,44D1CF,111111,2016/02/05,04:51:22.932,2016/02/05,04:51:22.893,,27025,,,,,,,0,,0,0
The possible timestamp candidates are each spread across two columns for date and time. A transform definition of
{
"type": "expression",
"name": "__time",
"expression": "timestamp_parse(concat(\"DMG\", ' ', \"TMG\"), 'yyyy/M/d HH:mm:ss.SSS')"
}
can concatenate the date and time fields and parse them according to the custom format.
Use a case expression inside a transform
If you want to roll up ordinal (or categorial) data into bigger buckets, you can use a case expression. Like in SQL, it comes as either a simple or searched case expression. A case_simple call compares a field against constant values of the same expression. A case_searched call is more flexible and can specify a sequence of arbitrary conditions and values (and a fallback value at the end).
Here’s an example where I classify the temperature as “hot” if it is above 40°C, “warm” between 20°C and 40°C, and “cold” otherwise.
{
"type": "expression",
"expression": "case_searched(tempC > 40, 'hot', tempC > 20, 'warm', 'cold')",
"name": "tempInd"
}
Use a temporary array for word processing
This is great for processing of unstructured data such as headlines or search engine keywords.
Split up the words in a string
Our friend here is the string_to_array function. Its second argument is actually a regular expression, so we can write a transform spec like this
{
"type": "expression",
"expression": "string_to_array(page, '\\\\s+')",
"name": "page_words"
}
to extract the individual words out of the page field. The result will be interpreted as a multi-value dimension.
Count words (n-grams)
Or we can collapse this array again. If we want to just know how many words are in the string, we determine the length of the array like so:
{
"type": "expression",
"expression": "array_length(string_to_array(page, '\\\\s+'))",
"name": "page_ngram"
}
Apply functions map-reduce style
Once we have a field split and parsed into an array, we can do list processing using lambda expressions. Here is an example that converts all the words into upper case:
{
"type": "expression",
"expression": "map((x)->upper(x), string_to_array(page, '\\\\s+'))",
"name": "page_words_upper"
}
Conclusion
Druid transforms are a handy tool to do elementary data massaging during ingestion. What we’ve learnt:
- Don’t try to use this capability to replace an ETL or ELT pipeline.
- If you write transforms directly into the ingestion spec, be aware of the quote escape rules.
- Simple math transformation are easy on this level.
- If you do math that involves integer expressions, be sure to force the numbers to floating point when needed.
- We can use transforms to do things that the built in parser does not handle well by default, like parsing composite timestamps.
- Arrays and lambda expressions open up additional possibilities.
“This image is taken from Page 500 of Praktisches Kochbuch für die gewöhnliche und feinere Küche” by Medical Heritage Library, Inc. is licensed under CC BY-NC-SA 2.0 ![]()
![]()
![]()
![]() .
.