Partitioning in Druid - Part 3: Multi Dimension (Range) Partitioning

This is part 3 of the miniseries about data partitioning in Apache Druid. Previous articles in this series:
Recap
In the previous articles, we learned that hash partitioning is great at ensuring uniform segment size. Single dim partitioning can group data according to frequent query patterns - however, if the partition key has a skewed distribution you may end up with very uneven segment sizes.
Range Partitioning fixes this problem. At the time of this writing it isn’t part of the standard Druid release yet - it is slated to be released with Druid 0.23. But you can get a sneak peek when you build the current snapshot from the source.
Range (or Multi Dimension) Partitioning
Range partitioning works by allowing a list of dimensions to partition by, effectively creating a composite partition key. Note that this is not a multi-level partitioning scheme as some databases know it. Rather, if a value in the first listed dimension is so frequent that it would create a partition that is too big, the second dimension is used to split the data, then the third, and so on.
Also, data is sorted by this composite key. This has the effect that a query that groups or filters by all (or the first n) of the partition key columns will run faster. In this respect it works a bit like composite indexes in databases.
It will also reduce overall segment size because data that are sorted this way can be compressed more efficiently.
As mentioned above, you will have to build your own snapshot Druid version to try this out. If you follow the steps below with the standard 0.22 release, you will not get an error. But Druid will fall back to hash partitioning.
(Or you can use Imply’s version which has multi dimension partitioning already built in.)
Range partitioning is not supported by the web console wizard, so we have to resort to a little trick. As before, I’ll show this with the quickstart wikipedia dataset.
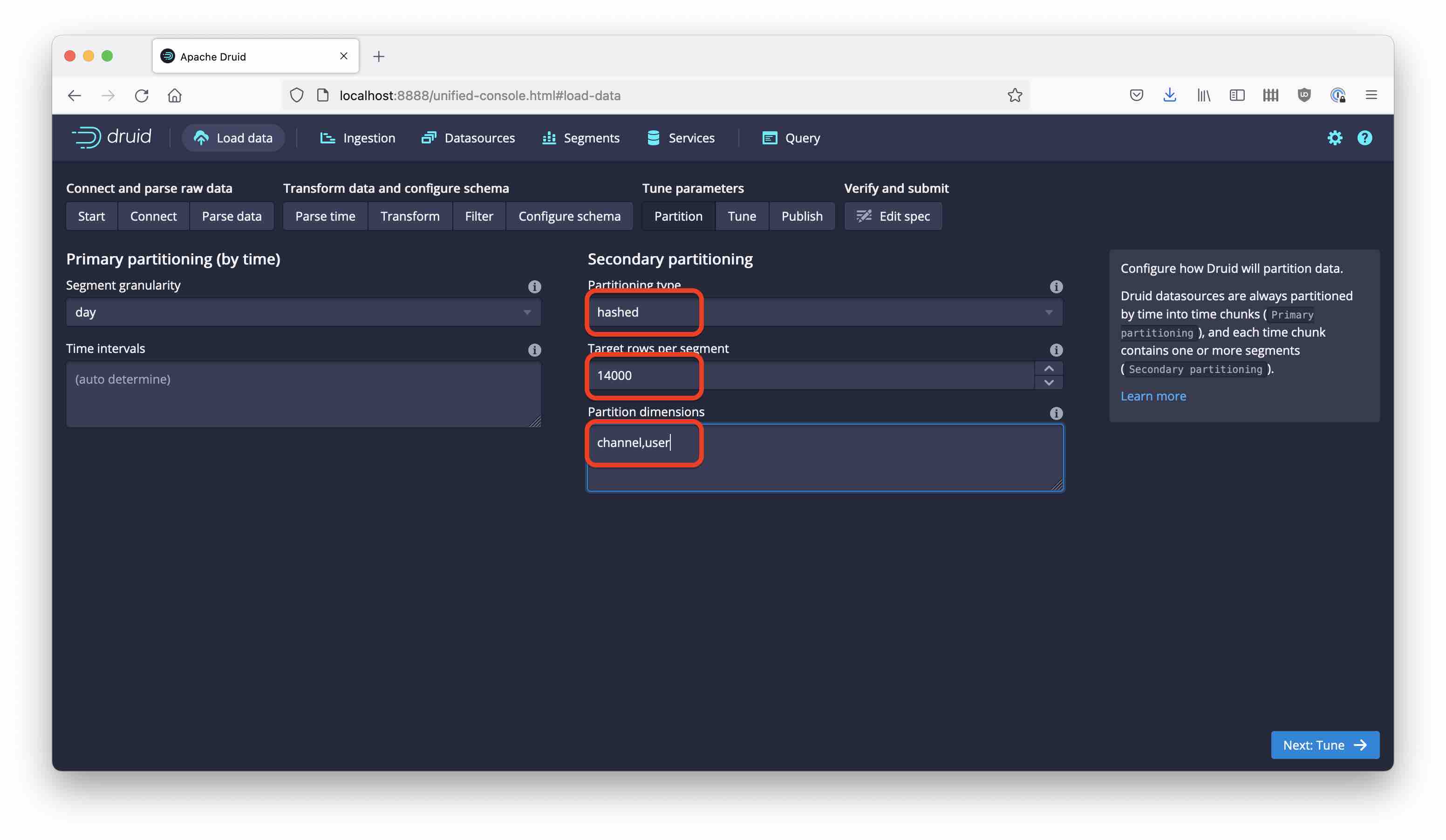
Configure your ingestion just like in part 1, pretending that you want to do do a hash partitioning. Name the new datasource wikipedia-range. Set the segment size to 14,000 rows; however, this time, enter both channel and user as the partitioning column:
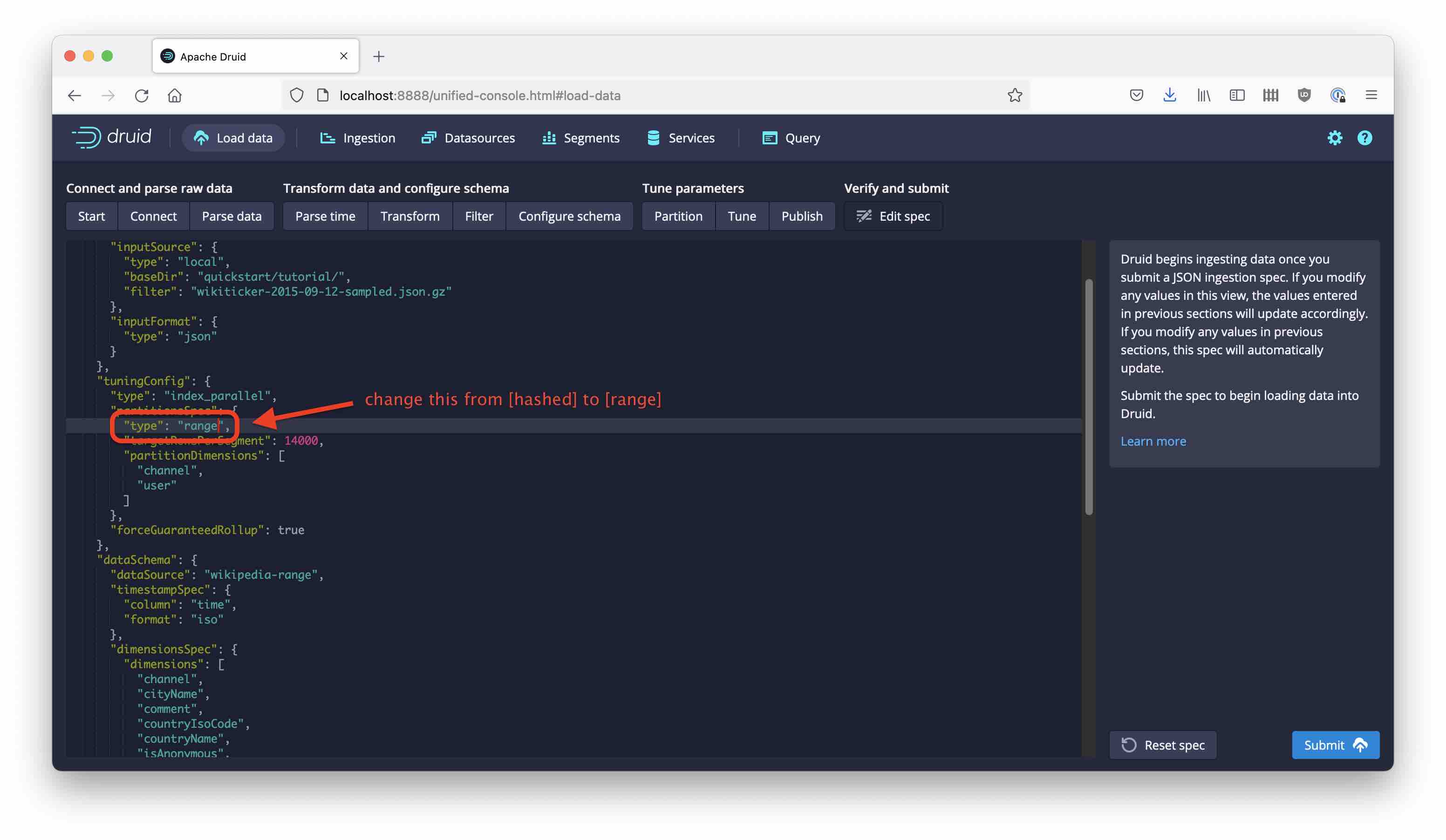
Then, continue in the wizard until you get to edit the JSON Spec. On this screen, look up the partitioning configuration and replace the word hashed by range:
Click Submit and let the ingestion task finish.
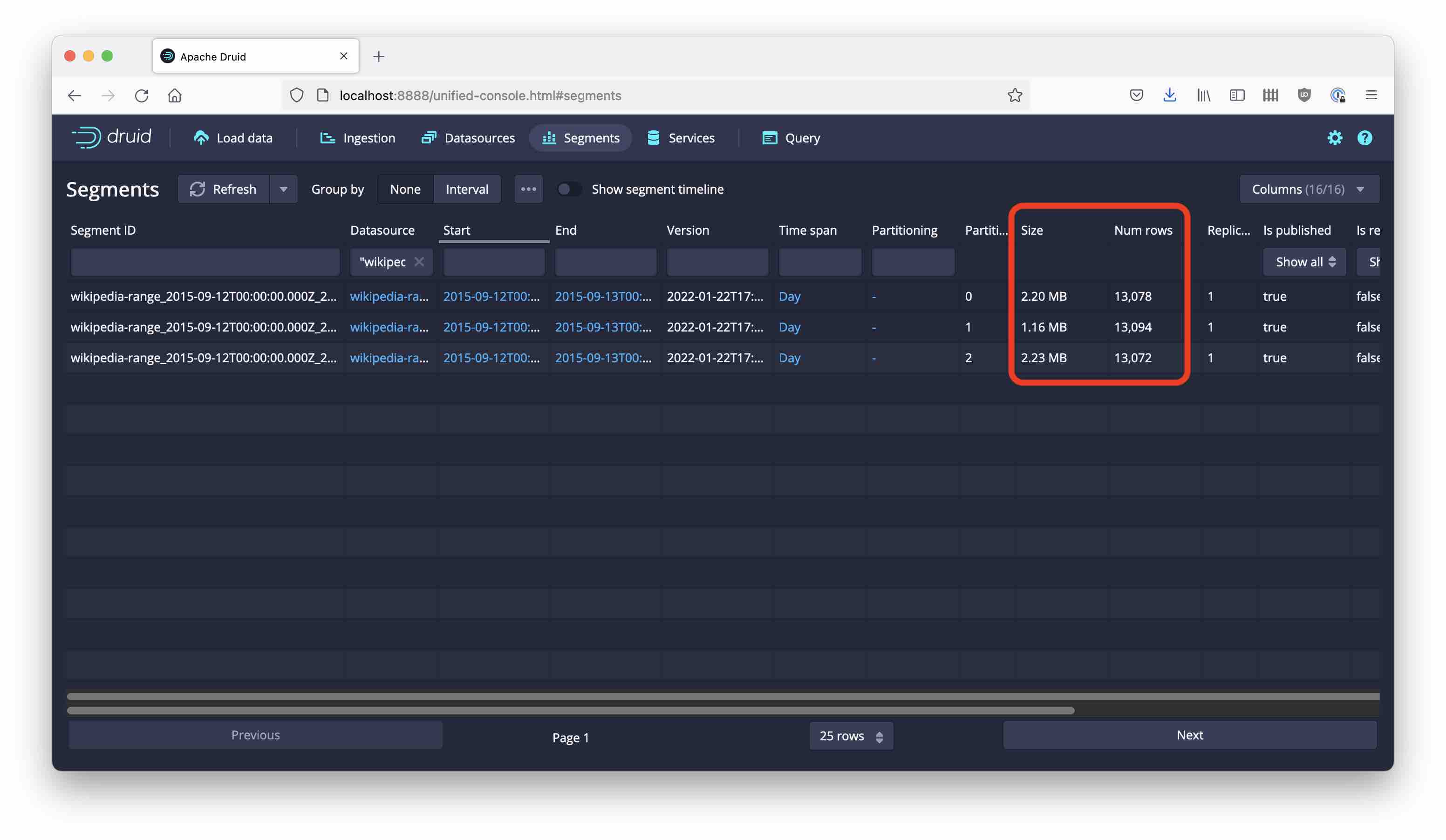
This time, we get a nice and even distribution of rows among the segments:
Run a native query to look at the segment metadata like last time, but include both key columns in the query:
{
"queryType": "segmentMetadata",
"dataSource": "wikipedia-range",
"intervals": [
"2013-01-01/2016-01-01"
],
"toInclude": {
"type": "list",
"columns": [
"channel", "user"
]
}
}
The values of the leading channel dimension are nicely bucketed in alphabetic order:
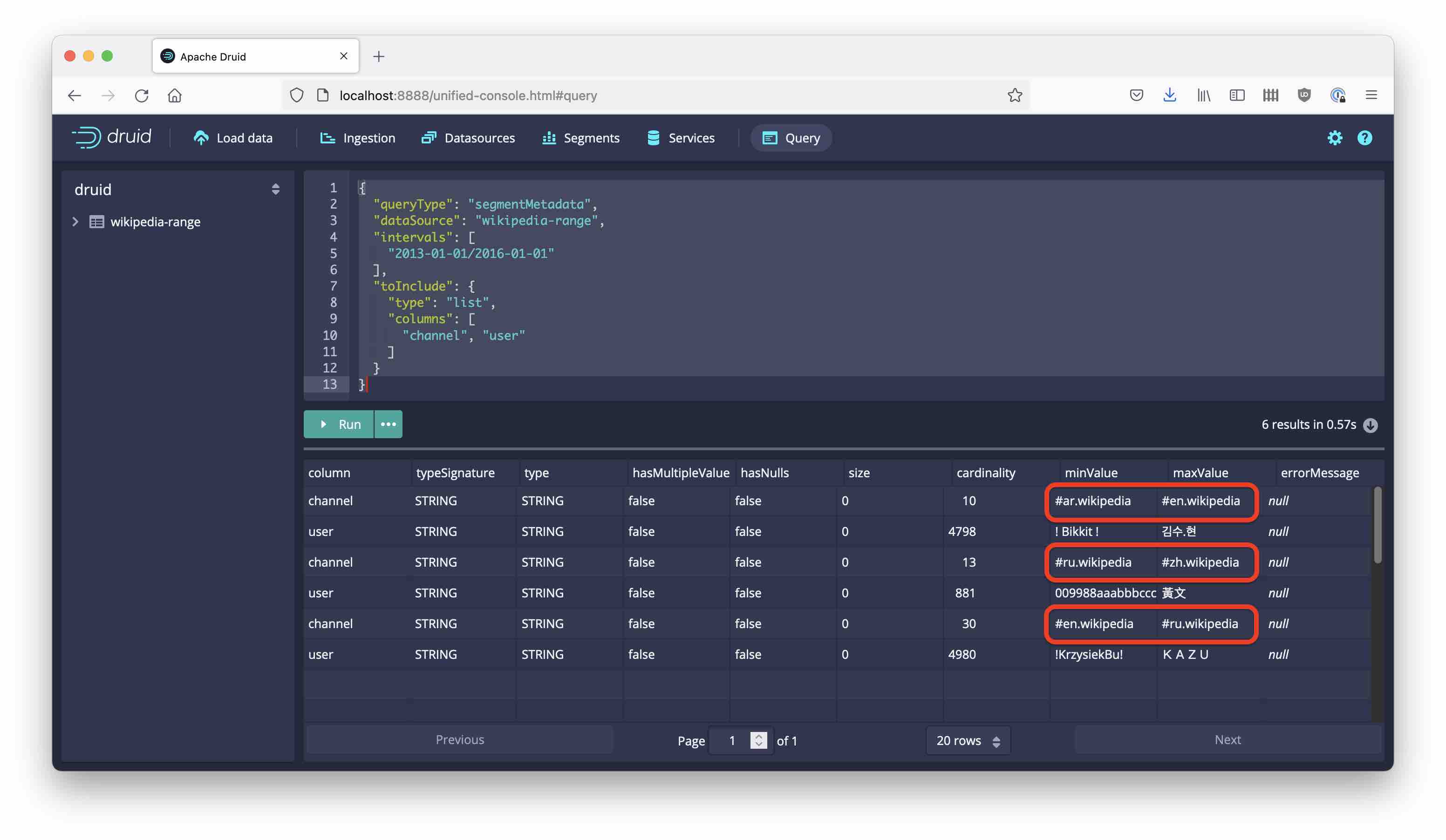
Note how the “boundary” values (en and ru, respectively) are now distributed among two partitions. This is how multi dimension partitioning works - in these cases the second key column user breaks the tie.
Here are the top 5 channel values for each partition:
Partition 0:
8917 #en.wikipedia
2523 #de.wikipedia
478 #ca.wikipedia
423 #ar.wikipedia
251 #el.wikipedia
Partition 1:
9747 #vi.wikipedia
1126 #zh.wikipedia
983 #uz.wikipedia
263 #uk.wikipedia
247 #ru.wikipedia
Partition 2:
2632 #en.wikipedia
2099 #fr.wikipedia
1383 #it.wikipedia
1256 #es.wikipedia
1139 #ru.wikipedia
Learnings
- Multi dimension partitioning is new and will (likely) be part of the next Druid release.
- It gives you benefits if you have frequent query patterns that use the same subset of columns for filtering and grouping.
- Like hash partitioning, multi dimension partitioning can ensure uniform segment sizes.
“Remedy Tea Test tubes” by storyvillegirl is licensed under CC BY-SA 2.0, cropped and edited by me