Druid Lab - Processing Movie Tag Data

Let’s look at some of the data engineering tricks that you might need when processing real world data with Apache Druid.
There is a moderately large, free dataset that has movie tag and synopsis data from IMDB. You can obtain it in various places, for instance here. The data is in CSV format, which should be easy to parse and ingest. Right?
Cleaning the Data
Let’s go through with a standard ingestion. I am reading the file locally into a quickstart instance, but you could as well keep it in S3 or another cloud storage service. Configure the parser to use CSV and derive the field names from the header, and …
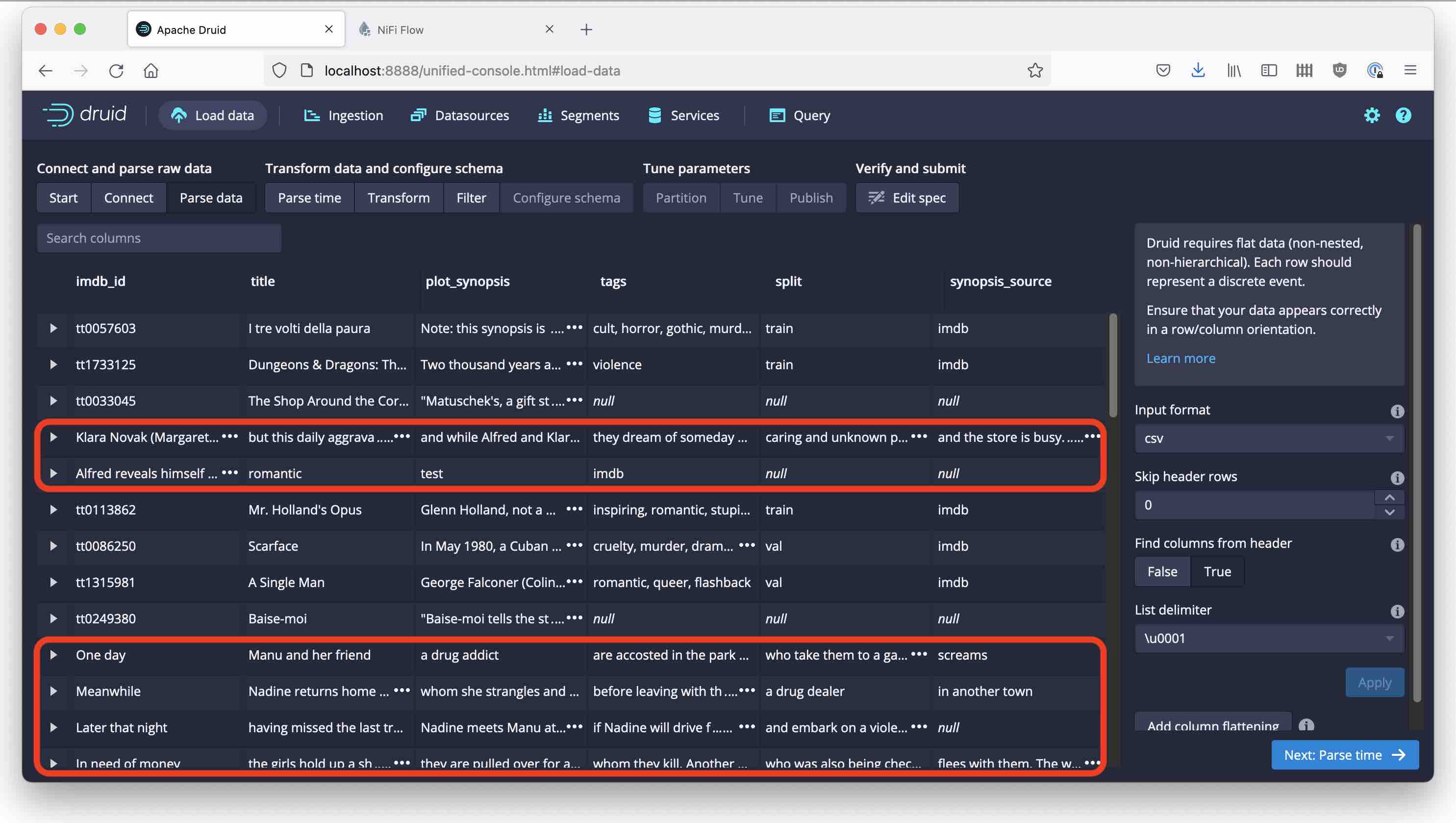
This does not look good! What happened here?
Apparently, the plot_synopsis field of our data file contains multi-line strings. Druid’s parser cannot handle linefeeds inside CSV fields, so we need to resort to some preprocessing. If we can somehow parse the CSV, replace all the linefeeds inside the data field with spaces, and write the result back, we should be fine.
NiFi to the rescue!
A very easy graphical tool that can be used for data cleansing is Apache NiFi. With NiFi, it is easy to set up a data flow like this:
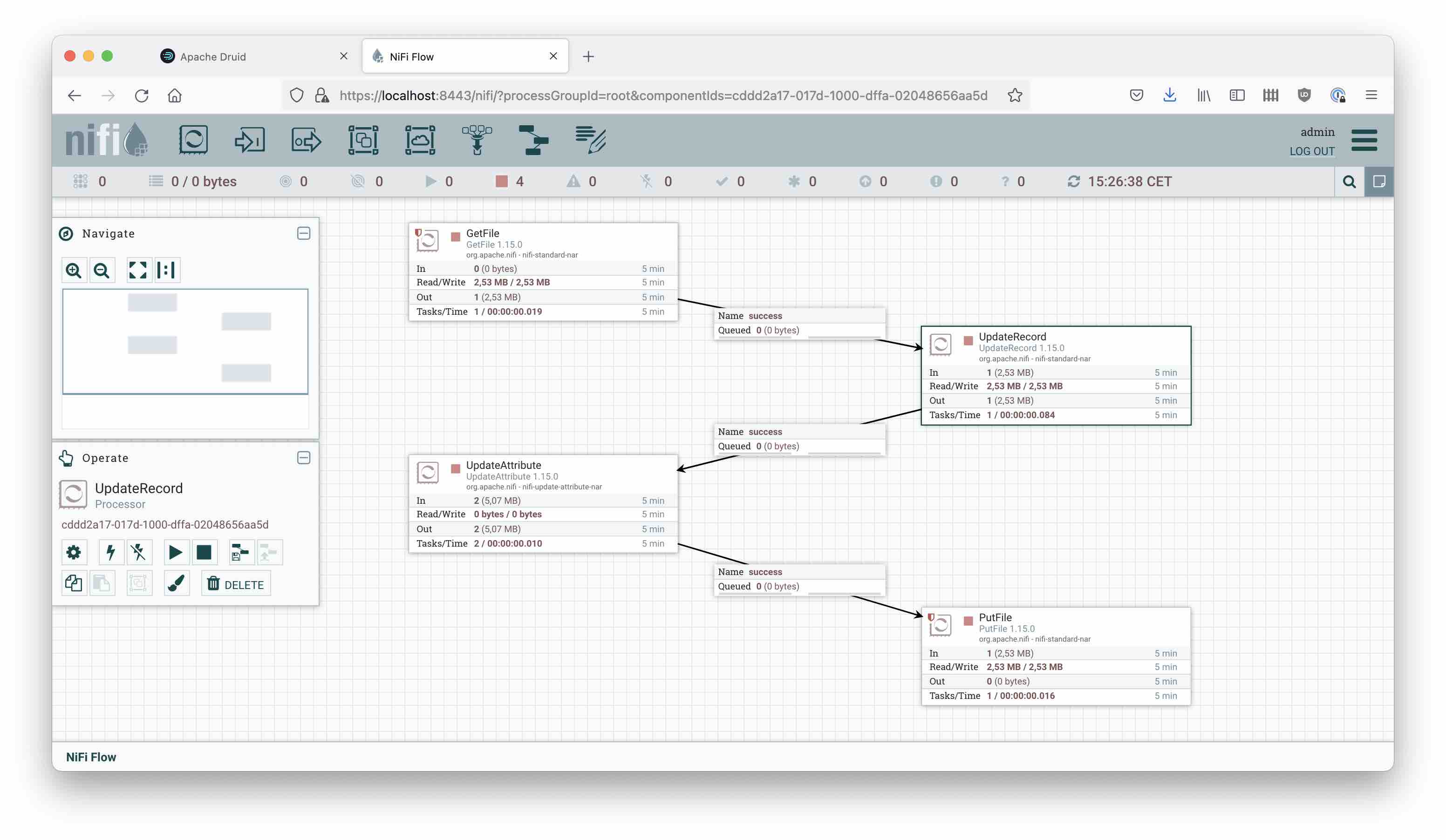
So, we read the original file and feed the result into an UpdateRecord processor. This processor parses its input using a CSV Reader, and then replaces the plot_synopsis field like this:
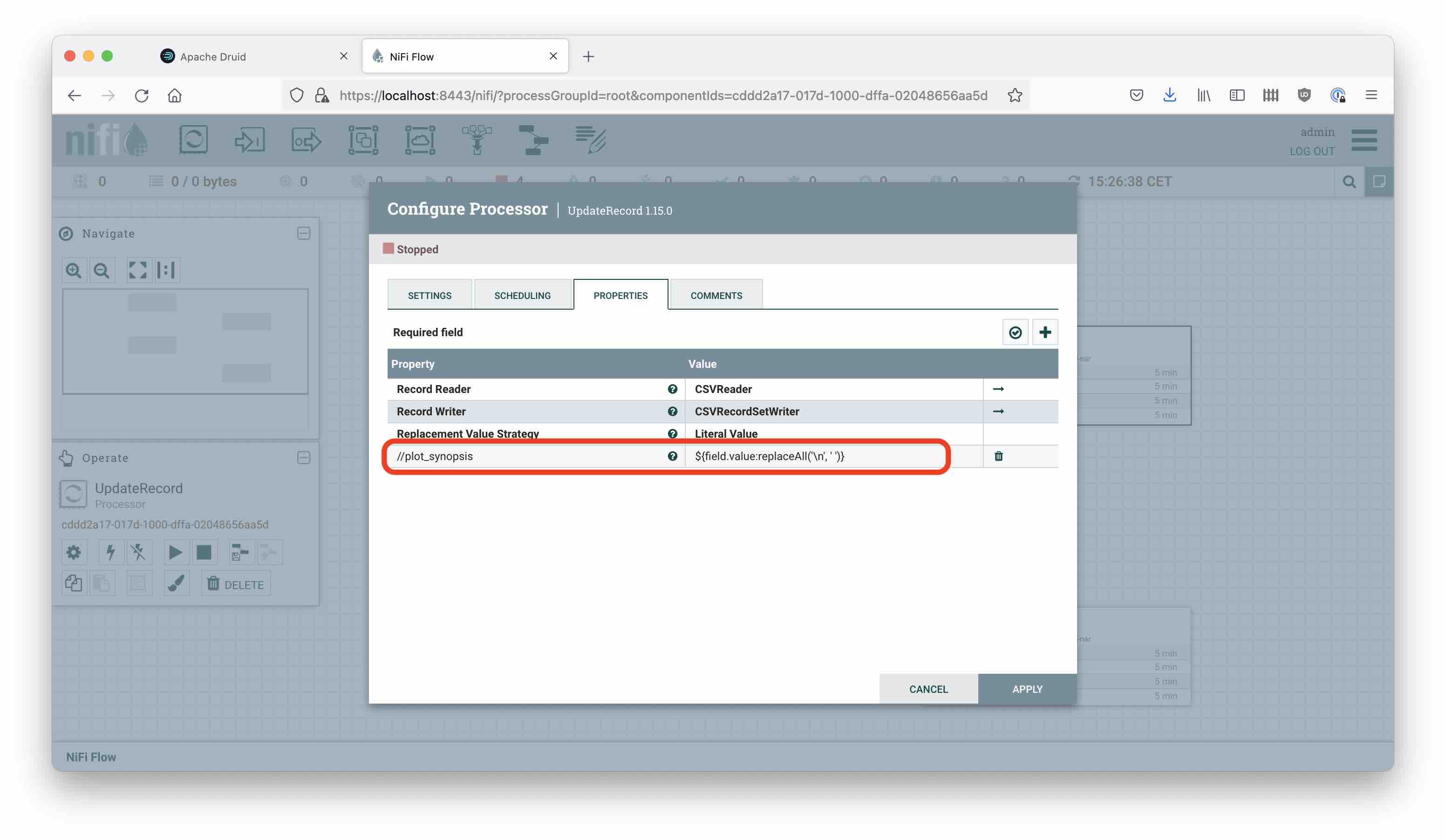
The rest is about giving the file a new name, and writing it back. Once we have done this, the result in Druid looks much better. But we have a new problem: the tag field’s internal delimiter is a comma ,, the same as the field delimiter!
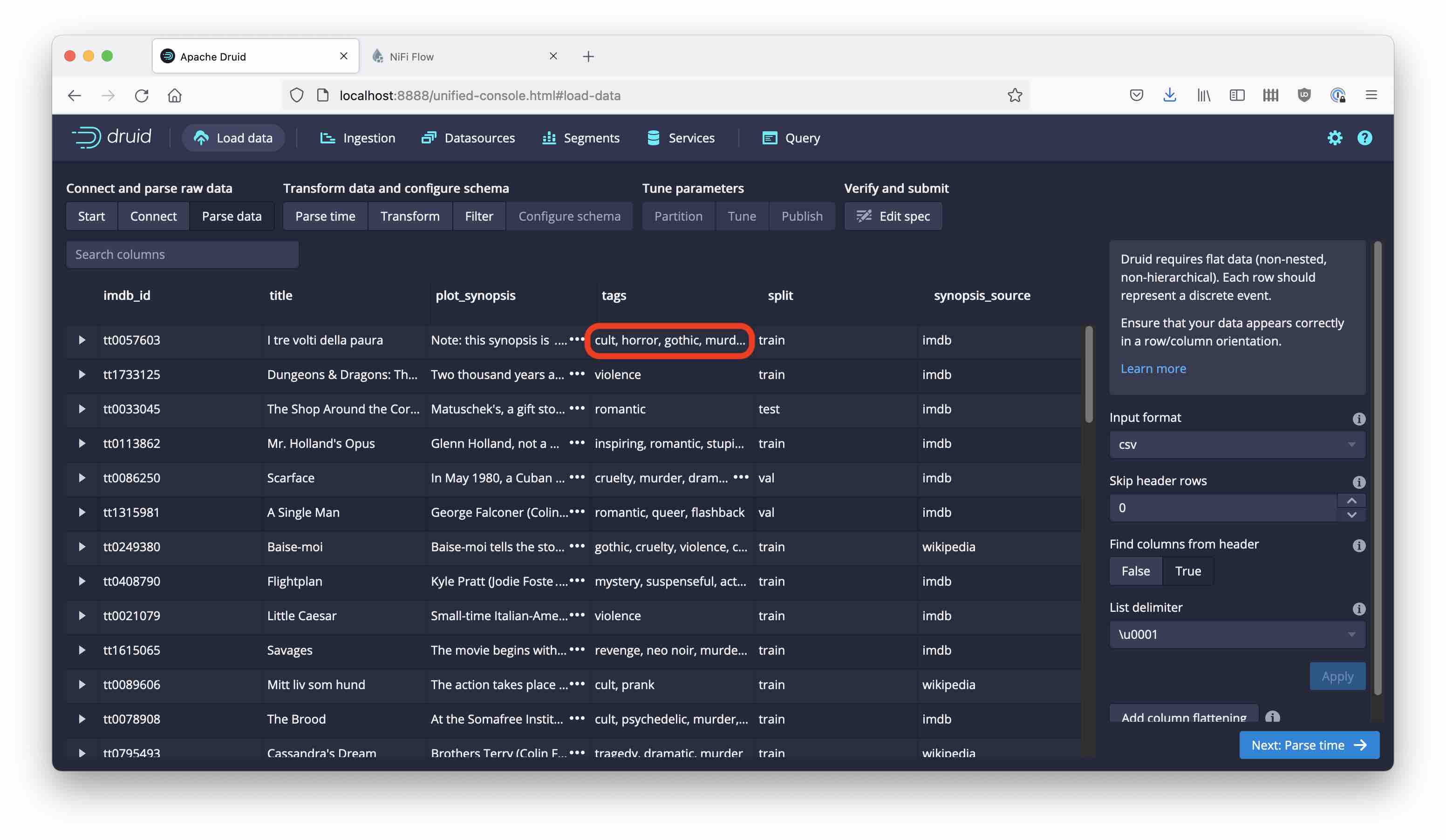
Parsing the Tag List, 1st Attempt
You cannot use the same character for the field and list delimiters in the Druid wizard. (You can try it: you will get an error.) But there’s another thing we can do: we can build the multi-value tags dimension using a transform! Let’s try this: create a new transform and use this expression:
string_to_array(tags,',')
Here’s the result. It looks quite good …
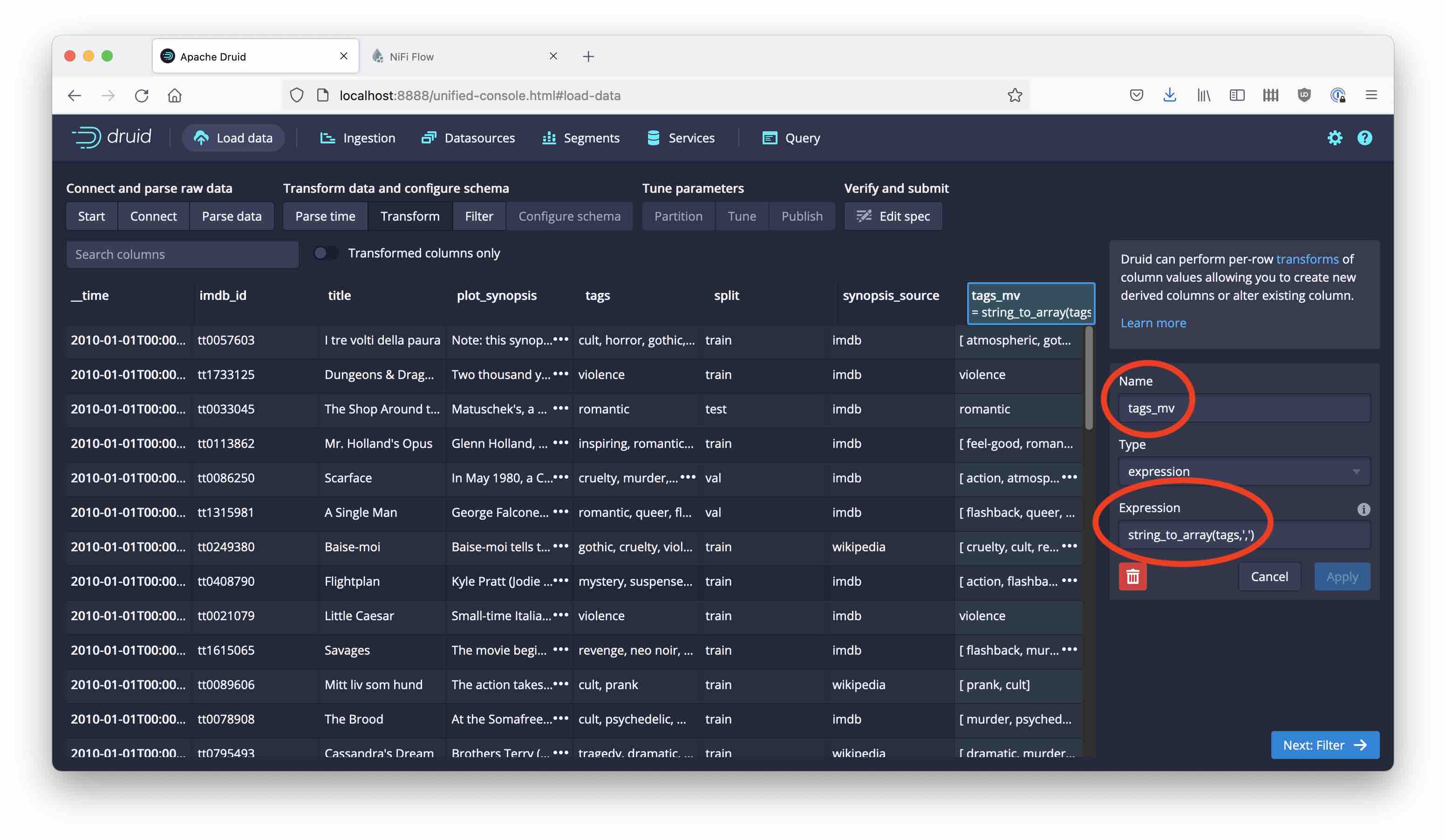
… but we are not done yet! If you look closely, you notice that there are extra spaces in the tags that shouldn’t be there:
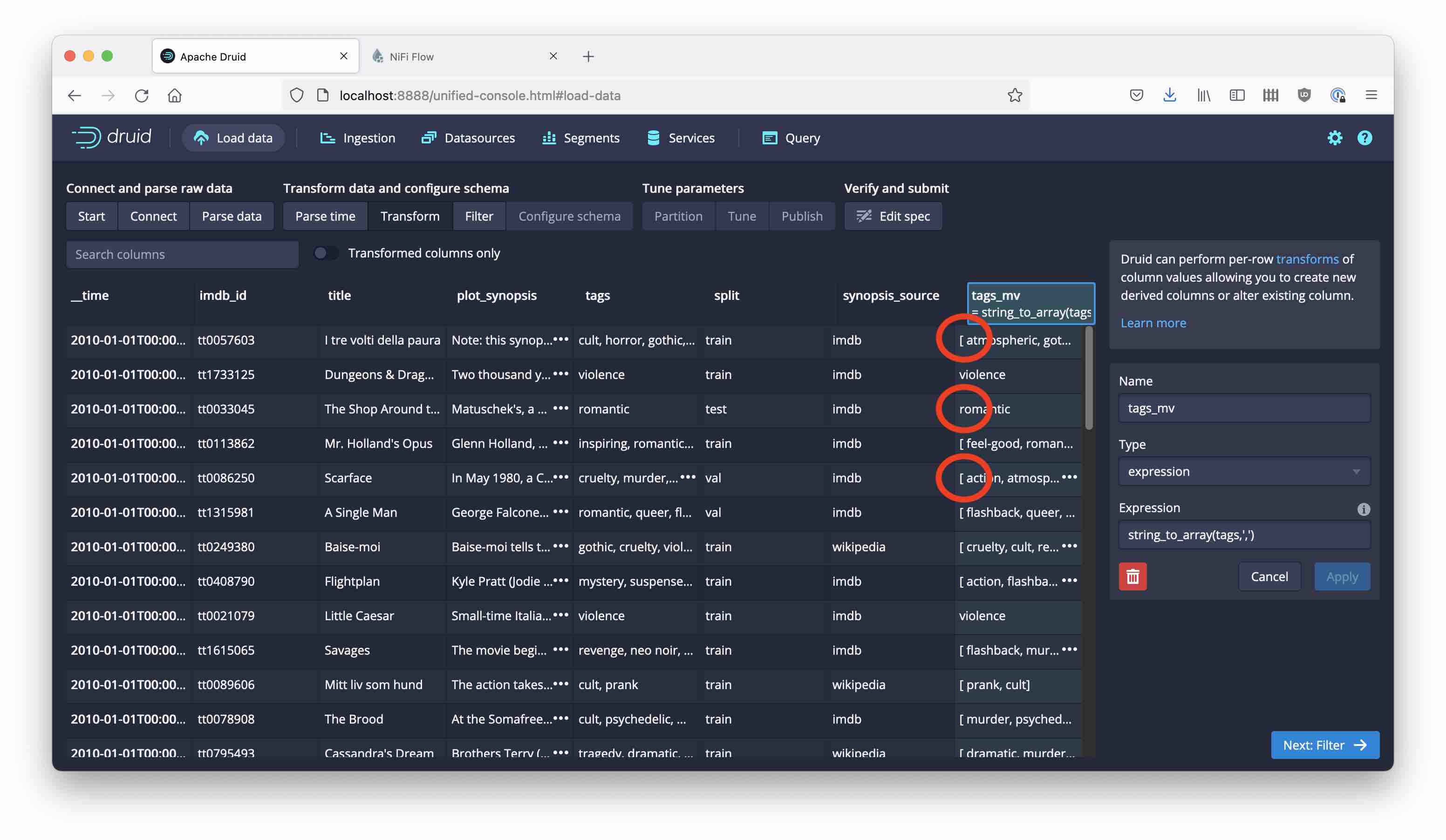
This is because the tags in the original data are separated by a sequence of comma and space. What can we do here?
Flexible Splits
A poorly documented feature of the string_to_array Druid function is that its second argument is actually a regular expression. So, why don’t we solve this properly and split the string by (comma and any amount of whitespace)!
The expression to enter is:
string_to_array(tags,',\\\\s+')
because we need to double escape the backslash \ in order to protect it from the parser.
(Side note: You could also use this function in a native Druid query. The equivalent in Druid SQL is called STRING_TO_MV; we talked about its counterpart MV_TO_STRING earlier.)
With this, the result looks much better!
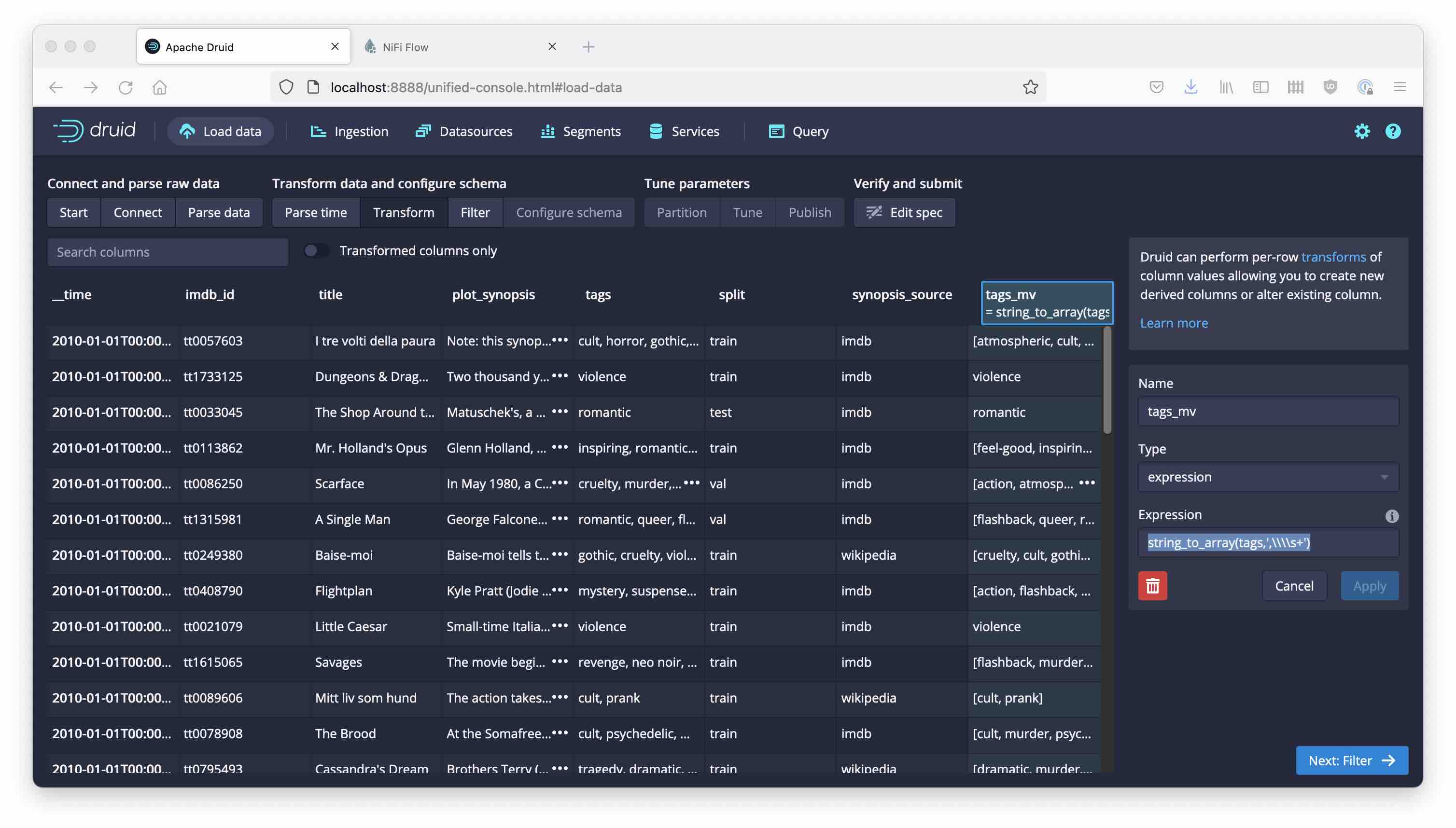
If you follow up from here, you may find that there are still some more bad apples in the data. For a real production project, this would be the first iteration of several. But I hope I have been able to show some principles!
Learnings
- If you cannot parse a multi-value dimension directly, you may be able to use a transform to build it.
string_to_arrayis a powerful function to split a string dimension into multiple values using regular expressions.- You can use Apache NiFi to preprocess any formats that you have trouble reading directly.
Image source: Derived from: “Delite Cinema” by Sun Pictures / Lakshman is licensed under CC BY-NC-SA 2.0