Druid Lab - Generating a Tag Cloud Using Rule Based Text Processing
Here’s an interesting situation I came across in one of my projects:
The client has clickstream data in the broadest sense. For classifying the page clicks, they had a number of content groups and they wanted to count their metrics by content group.
What they did in their existing system looked something like this:
WITH cte AS (
SELECT
'keyword1' AS keyword_group, url, clicks, impressions, ...
FROM data
WHERE <set of complex rules>
UNION ALL
SELECT
'keyword2' AS keyword_group, url, clicks, impressions, ...
FROM data
WHERE <another set of complex rules>
... and so on ...
)
SELECT keyword_group, COUNT(DISTINCT url), SUM(clicks), SUM(impressions) ...
FROM cte
GROUP BY keyword_group;
So, there is a long list of conditional queries that are glued together by UNION ALL clauses. This was slow and hard to maintain.
It turns out that this type of query pattern can be very elegantly modeled in Apache Druid with multi-value dimensions (MVD). Let’s give it a try!
As usual, I am going to use a tiny data set that I am pasting directly into the wizard:
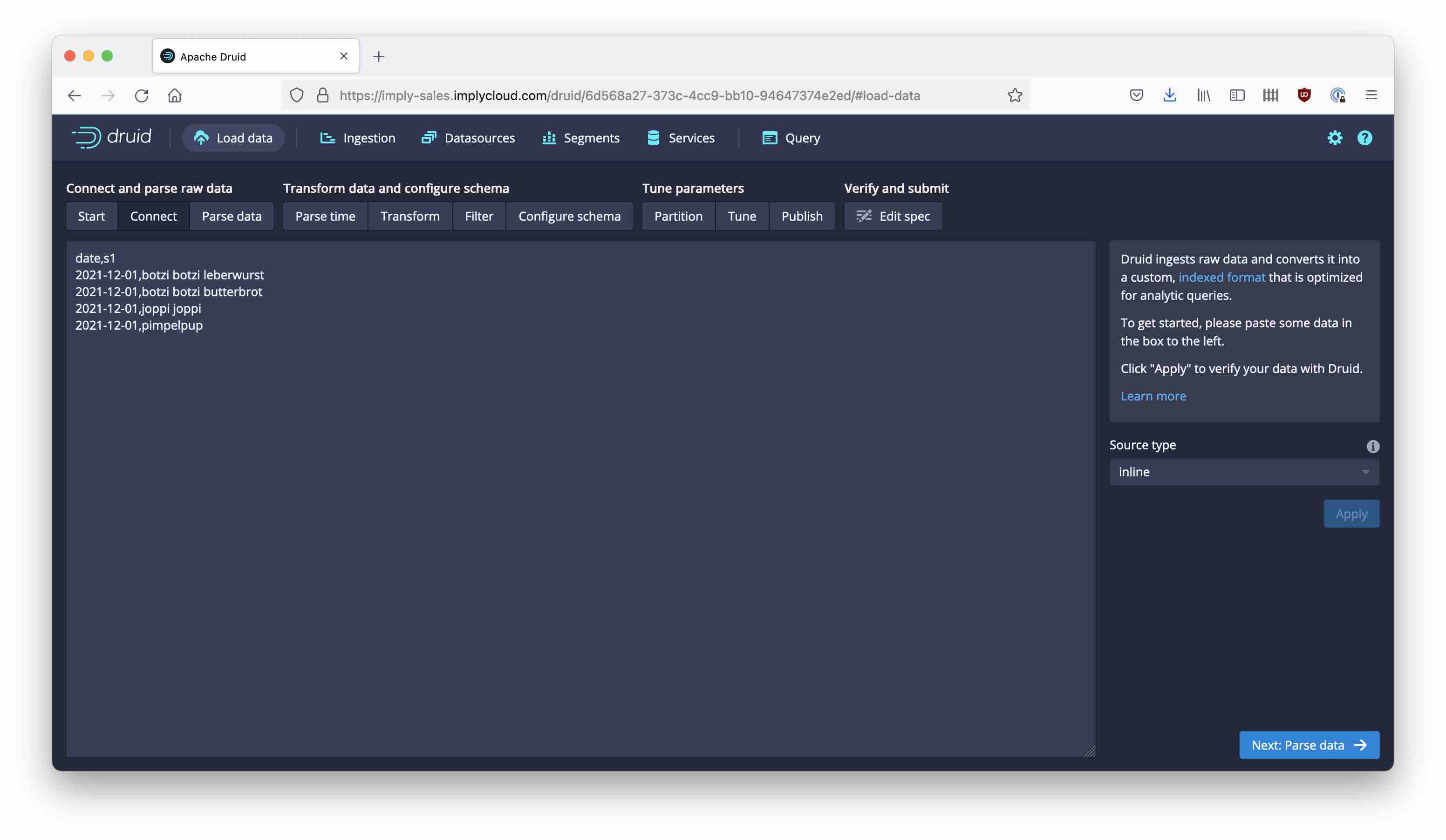
Parse this as csv and proceed to the Transform stage in the wizard.
We are going to assign tags to the text bits (which happen to come from one of my youngest boy’s kids books), and we are going to apply two different sets of rules:
- We are assigning language tags according to the occurrence of certain words. The little monkey says “botzi”, so we can identify its phrases using a simple substring search. The little alien has some more keywords, so it’s going to be a regular expression with an alternative.
- We are also interested in groups of 2 or 3 words: digrams and trigrams. These are picked out using slightly more complex regular expressions that look for specific sequences of whitespace and non-whitespace.
In the Transform wizard, hit Add column transform.
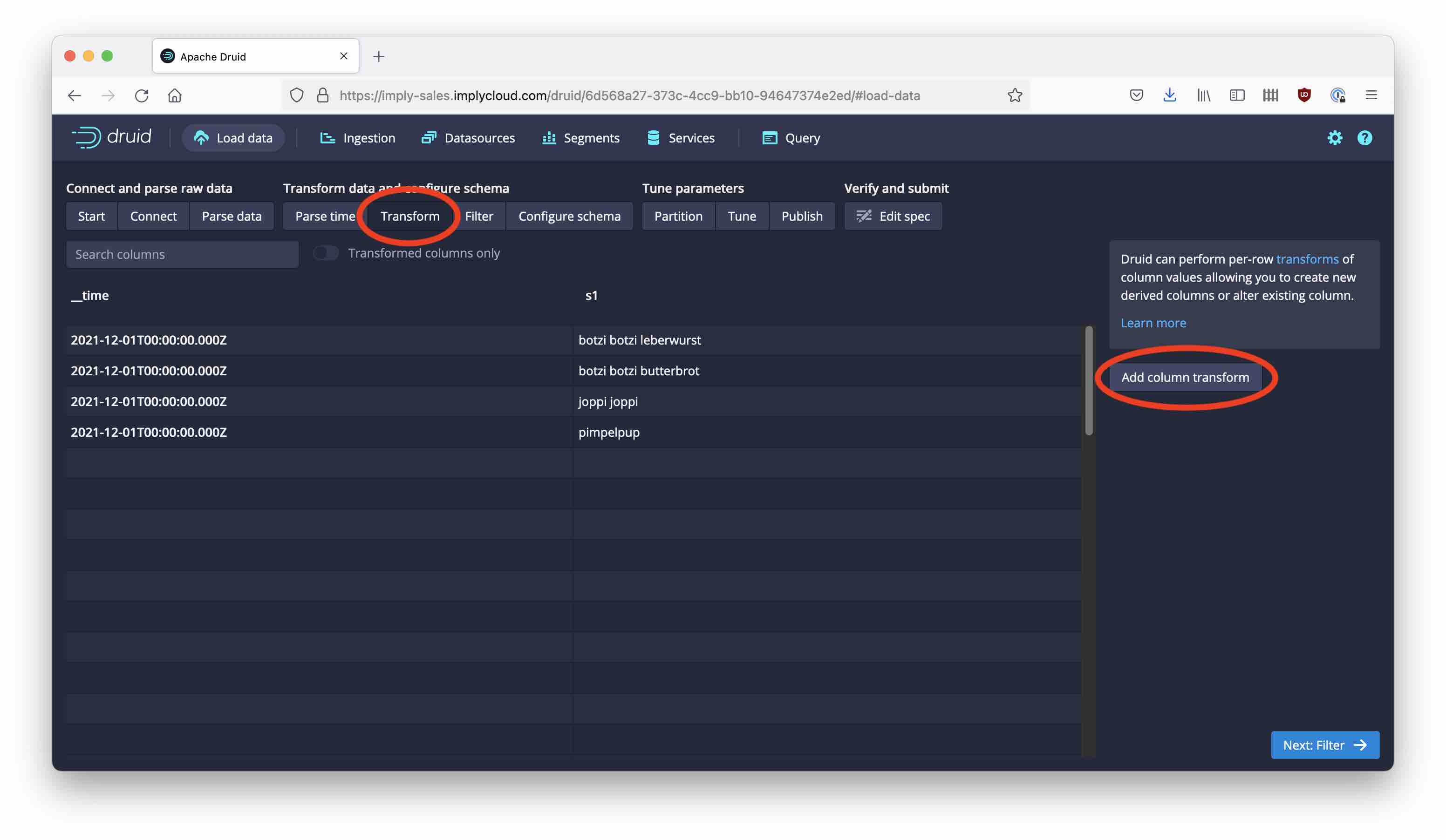
Name the new transform keyword_group.
Here comes the magic!
For the transformation expression, enter this text:
filter((x) -> x != null, array(
if(contains_string(s1,'botzi'),'monkeyspeak',null),
if(regexp_like(s1,'^\\\\S+?\\\\s\\\\S+$'),'digram',null),
if(regexp_like(s1,'^\\\\S+?\\\\s\\\\S+?\\\\s\\\\S+$'),'trigram',null),
if(regexp_like(s1,'joppi|pimpelpup'),'alienspeak',null)
))
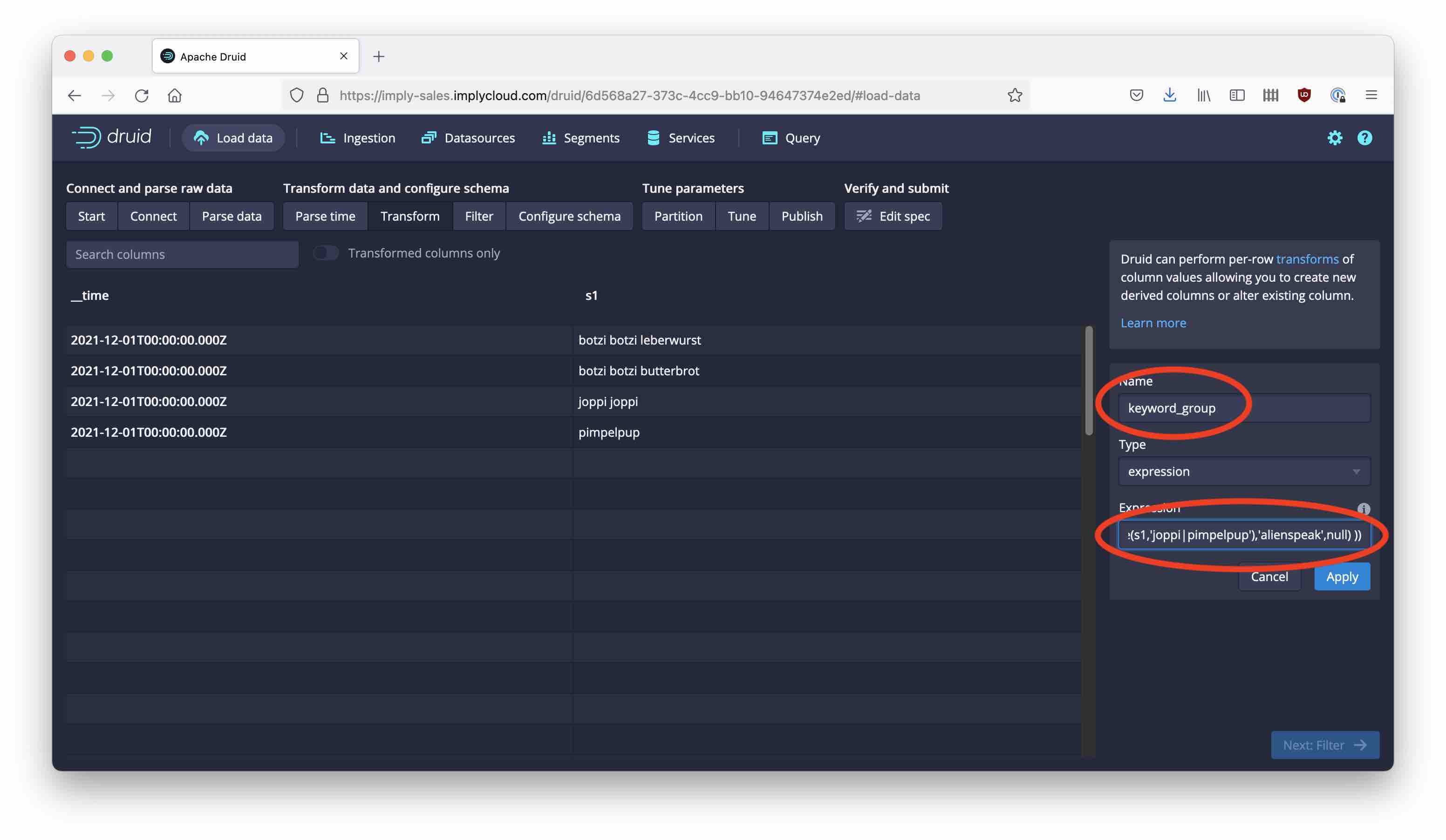
What have we done here?
- Each of the
iflines generates a string value if the condition is met, or null if not. (Note that do to some peculiarity of the regex parser, we need four backslashes where we want to use one.) - The
array()constructor makes these neatly into an array, ready to processed as an MVD. - Finally the
filter()clause squeezes out all the null values that we don’t want in here. This is a relatively new addition in Druid: you can define lambda expressions to be used in map and filter operations.
Look at the result:
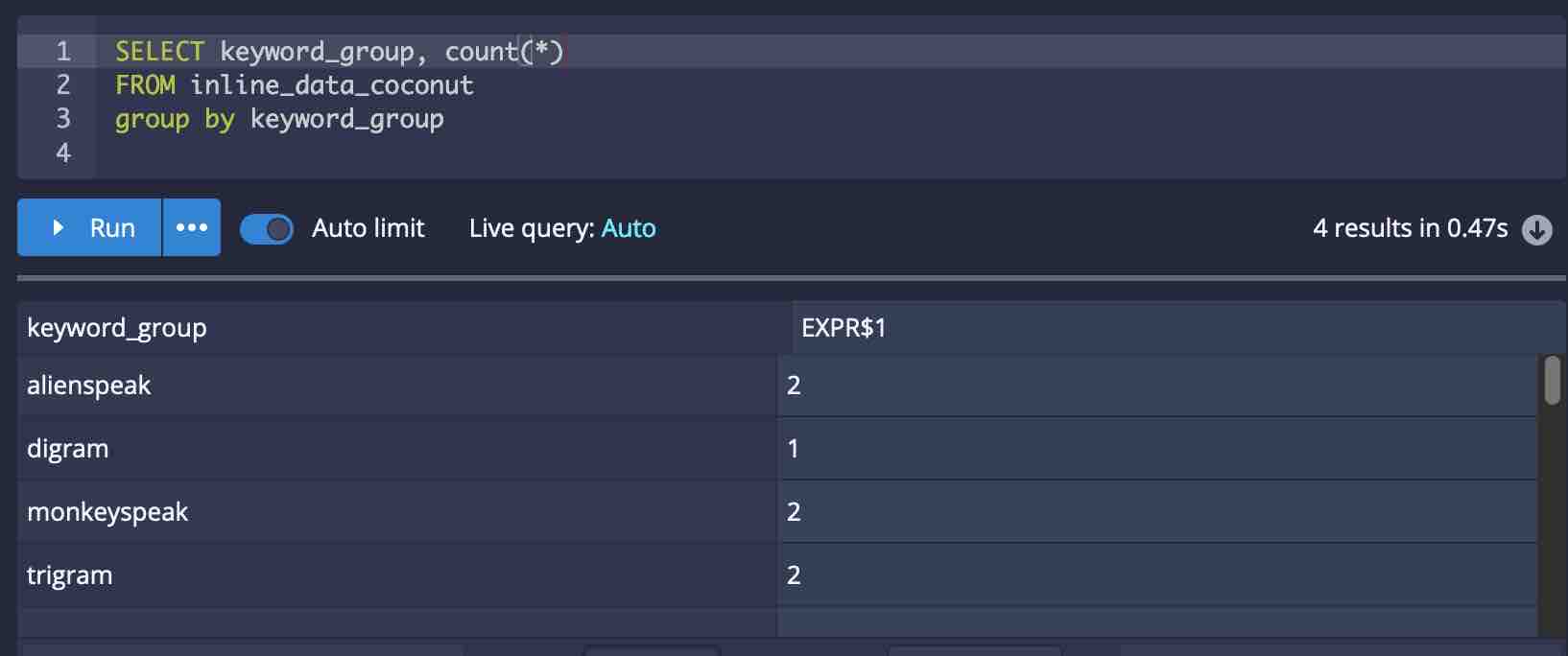
The original query has been much simplified!
Learnings
- Multi-value dimensions can not only be parsed from the data - you can also generate your own!
- Druid comes with powerful functions like
mapandfilterwhich, together with lambda expressions, create an elegant way to manipulate multi-value dimensions. - This can greatly simplify common query patterns in analyzing online behavior data.